13. Werkzeuge zur Fehlersuche im Netzwerk
Verschiedene Werkzeuge eignen sich zur Fehlersuche im Netz. Einige verwende ich immer wieder bei den unterschiedlichsten Problemen, andere sind spezialisiert auf bestimmte Fragestellungen.
Hier stelle ich diejenigen, die ich am häufigsten einsetze, in alphabetischer Reihenfolge vor.
arp
Das Programm arp dient der Anzeige und Manipulation des ARP-Caches des
Kernels.
Ich setze es bei Problemen in direkt angeschlossenen Netzsegmenten ein und
verwende es
- um die Zuordnung von IP-Adressen zu Ethernet-Adressen zu verifizieren
- um zu sehen, ob ein Rechner eine IP-Adresse verwendet, auch wenn ich keine Antwort auf TCP-, UDP- oder ICMP-Verbindungsversuche (Ping) bekomme.
- seltener: um eine Zuordnung zwischen IP-Adresse und Ethernet-Adresse fest vorzugeben.
Der prinzipielle Aufruf ist:
# arp [Optionen] [$rechnername]
Bei Aufruf ohne Optionen zeigt arp die MAC-Adressen an, die $rechnername
zugeordnet sind. Fehlt $rechnername, zeigt es alle bekannten
Adresszuordnungen an.
$rechnername kann ein Hostname sein, ein FQDN oder eine IP-Adresse.
Die für die Fehlersuche wichtigsten Optionen sind:
- -n
- unterlässt die Namensauflösung der IP-Adressen
- -d $rechnername
- entfernt alle Einträge für $rechnername
- -s $rechnername $hardwareadresse
- setzt den Eintrag für $rechnername auf $hardwareadresse
Für weitergehende Informationen verweise ich auf die Handbuchseite. Nähere Informationen zum ARP-Protokoll stehen im Grundlagenkapitel für Netze.
Wenn ich arp verwende, um mich von der Anwesenheit eines Rechners mit einer
bestimmten IP-Adresse im Netz zu überzeugen, sieht das wie folgt aus:
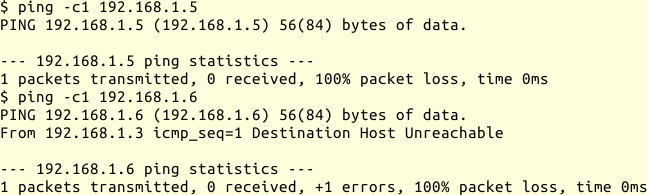
PING-Test im localen Netz
Ich habe von keiner der beiden Adressen eine
Antwort auf die PING-Anfrage bekommen.
Bei 192.168.1.6 kam jedoch nach kurzer Verzögerung die Meldung
Destination Host Unreachable, die bei 192.168.1.5 fehlte.
Bei der Kontrolle des ARP-Caches zeigt sich, dass für die eine IP-Adresse
eine MAC-Zuordnung gegeben ist, für die andere nicht.
$ arp -an
? (192.168.1.5) auf 00:01:6c:6f:c5:d6 [ether] auf eth0
? (192.168.1.6) auf <unvollständig> auf eth0
...
Das lässt vermuten, dass auf dem Rechner mit IP-Adresse 192.168.1.5 PING
durch Paketfilterregeln blockiert wird, während in diesem Netzsegment zu
diesem Zeitpunkt kein Gerät die IP-Adresse 192.168.1.6 für sich beanspruchte.
bridge-utils
Es gibt mehrere Szenarien, in denen ich mich bei der Fehlersuche mit Layer2-Bridges beschäftige. Zum einen, wenn ich einen verdächtigen Rechner habe und zur Kontrolle jeglichen Netzverkehrs eine Bridge vor seinen Netzanschluß schalten will. Oder, wenn ich den Verkehr auf einer Punkt-zu-Punkt-Verbindung kontrollieren will. In diesen Fällen möchte ich das restliche Netzwerk möglichst unverändert lassen und keinen anderen Rechner umkonfigurieren, um das Problem beobachten zu können. Mit einer Bridge bekomme ich allen Datenverkehr an der betreffenden Stelle frei Haus geliefert. Bis 100 MBit/s eignen sich beispielsweise Einplatinenrechner, wie in [Weidner2012] beschrieben, sehr gut dafür. Ein weiteres Szenario ist eine regulär betriebene Bridge, die scheinbar nicht funktioniert und die ich mit den bridge-utils untersuchen kann.
Prinzipiell kann ich mit einer Linux-Bridge den Verkehr filtern und
begrenzen. Dafür verwende ich auf Layer2-Ebene ebtables und auf
Layer3-Ebene iptables, bei letzteren benötige ich für eine Bridge
einen Kernel ab Version 2.4.
Linux-Bridges können das Spanning Tree Protocol (STP) verwenden und ich kann sie auch zur Diagnose von STP-Problemen heranziehen, obwohl mir hier tcpdump oder wireshark genausogut weiterhelfen.
Generell konfiguriere ich eine Bridge mit brctl.
Mit ipconfig, ip oder einem DHCP-Client kann ich ihr dann eine IP-Adresse
zuweisen.
Das Bridge-Forwarding-Delay von circa 30 Sekunden kann bei DHCP-Clients
Probleme bereiten.
Wenn gar nichts geht, muss ich das Bridge-Interface mit statischen Adressen
konfigurieren.
Lässt eine Bridge keinen Traffic durch, suche ich im Verzeichnis
/proc/sys/net/bridge/ nach Dateien mit Namen die mit bridge-nf-* beginnen.
Diese legen fest, ob die betreffende Bridge Verkehr filtert.
Das kann ich abschalten, indem ich eine ‘0’ in die betreffende Datei schreibe:
# echo 0 \
> /proc/sys/net/bridge/bridge-nf-call-arptables
# echo 0 \
> /proc/sys/net/bridge/bridge-nf-call-ip6tables
# echo 0 \
> /proc/sys/net/bridge/bridge-nf-call-iptables
Mit dem Program brctl inspiziere und bearbeite ich
die Bridge-Konfiguration im Linux-Kernel.
Dabei verwende ich die folgenden Befehle um eine oder mehrere Bridge-Instanzen zu bearbeiten:
- brctl addbr $brname
- fügt eine neue Bridge-Instanz namens $brname hinzu.
- brctl delbr $brname
- entfernt die Bridge $brname.
- brctl show
- zeigt alle momentan bekannten Bridges und die ihnen zugeordneten Interfaces an.
Jede Bridge benötigt Ports, zwischen denen sie Ethernet-Pakete vermittelt. Diese bearbeite ich mit den folgenden Befehlen:
- brctl addif $brname $if
- fügt die Schnittstelle $if zur Bridge
mit Namen $brname hinzu. Das Interface muss ich mit
ifconfigoderipaktivieren. - brctl delif $brname $if
- entfernt Schnittstelle $if von Bridge $brname.
- brctl show $brname
- zeigt Informationen zur Bridge $brname.
- brctl showmacs $brname
- zeigt die der Bridge $brname momentan
bekannten MAC-Adressen an.
Um herauszufinden, an welcher Schnittstelle die betreffende MAC-Adresse zuletzt gesichtet wurde, bestimme ich die Adresse und den Port in den Zeilen, in denen bei Spalte
is local?der Wert ‘yes’ steht und ermittle mitifconfigoderipdie betreffende Ethernet-Schnittstelle.
$ /usr/sbin/arp -an
192.168.1.253 auf 00:16:3e:ca:72:4c ether auf br0
192.168.1.223 auf b8:27:eb:74:74:d5 ether auf br0
...
$ brctl showmacs br0
port no mac addr is local? ageing timer
1 00:00:e8:df:92:b0 yes 0.00
1 00:16:3e:ca:72:4c no 20.54
2 00:1f:d0:97:c4:55 yes 0.00
2 b8:27:eb:74:74:d5 no 7.98
...
$ ip l sh
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
master br0 state UP qlen 1000
link/ether 00:1f:d0:97:c4:55 ...
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
master br0 state UNKNOWN qlen 1000
link/ether 00:00:e8:df:92:b0 ...
4: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
link/ether 00:00:e8:df:92:b0 ...
In diesem Beispiel ist der Rechner mit IP 192.168.1.223 an eth0 und der
Rechner mit IP 192.168.1.253 an eth1 angeschlossen, die über die Bridge
br0 miteinander verbunden sind.
Die Timer der Bridge kann ich mit den folgenden Befehlen ändern:
- brctl setageing $brname $time
- setzt den Timer für die Bridge $brname. Nach dem eine MAC-Adresse so viele Sekunden nicht gesehen wurde, wird die Bridge sie aus der Forwarding-Tabelle austragen.
- brctl setgcint $brname $time
- setzt das Intervall für die Garbage Collection auf $time. Aller $time Sekunden kontrolliert die Bridge die Forwarding-Tabelle nach veralteten MAC-Adressen.
ethtool, mii-diag, mii-tools
Mit ethtool, mii-diag oder mii-tool kann ich die Konfiguration
von modernen Ethernetschnittstellen anzeigen und manipulieren.
Die Programme verwenden dazu das Media Independend Interface (MII),
von dem sich auch der Name ableitet.
Welches Programm installiert ist, hängt von der Linux-Distribution ab. Ob ich es überhaupt verwenden kann, hängt von der Ethernetkarte ab. Moderne Ethernetkarten und die Onboardschnittstellen neuerer Rechner funktionieren meist gut mit diesen Programmen.
Ich kann mit diesen Programmen unter anderem:
- die Ethernet-Geschwindigkeit, das Duplexverhalten und das Aushandeln der Parameter mit dem Switch beziehungsweise der Gegenstelle einstellen oder abfragen
- die Wake-On-Lan-Konfiguration bearbeiten
- Selbsttests anstoßen
Gerade die Möglichkeit, Fehlanpassungen in der Geschwindigkeit oder beim Duplexverhalten zu erkennen, kann sich als wertvoll bei der Diagnose von Performanceproblemen erweisen.
Bei einer LWL-Verbindung hatten wir ernste Performanceprobleme, bei denen die Transferrate in einer Richtung auf wenige KB/s beim beidseitigen Lasttest herunter ging. Unser erster Gedanke war eine schlechte Faser, da das Problem nur in einer Richtung auftrat. Mit den mii-tools konnte ich eine Fehlanpassung der Ethernetkarte mit dem Medienwandler diagnostizieren. Nachdem ich die Schnittstelle auf Full-Duplex eingestellt hatte, blieb die verfügbare Datenübertragungsrate auch bei Volllast in beiden Richtungen im erwarteten Rahmen.
ifconfig
Mit dem Programm ifconfig kann ich die Netzwerkschnittstellen konfigurieren. Außerdem liefert es Informationen über den aktuellen Zustand und die Konfiguration der Netzwerkschnittstelle.
Es gibt drei Möglichkeiten ifconfig aufzurufen.
# ifconfig [-a]
zeigt den Status der aktiven Schnittstellen.
Gebe ich zusätzlich die Option -a, zeigt es den Status aller Schnittstellen,
also auch der inaktiven.
# ifconfig $schnittstellenname
zeigt den Zustand der angegebenen Schnittstelle an.
In der dritten Form,
# ifconfig $schnittstellenname $optionen
wird die Schnittstelle konfiguriert.
Die wichtigsten Optionen bei der Fehlersuche sind
- up
- zum Aktivieren von Schnittstellen
- down
- zum Deaktivieren
- mtn $N
- zum Setzen der Maximum Transfer Unit
- netmask $M
- zum Setzen der Netzmaske
- hw $A
- zum Setzen der Hardware-Adresse
Weitere Informationen liefert die Handbuchseite.
Es ist möglich, an eine Netzwerkschnittstelle mehrere IP-Adressen zu binden. Das Programm ifconfig arbeitet jedoch mit einer Adresse pro Schnittstelle. Um weitere Adressen an diese Schnittstelle zu binden, füge ich an den Schnittstellennamen einen Doppelpunkt und eine Zahl an.
In letzter Zeit werden die Netzwerkschnittstellen oft mit dem Programm ip
vom Paket iproute2 konfiguriert, welches in der Sektion über
iproute beschrieben ist.
Für den schnellen Überblick über die aktuelle Konfiguration der Schnittstellen
gefällt mir die Ausgabe von ip addr show besser, da sie kompakter
ist, was sich insbesondere dann auszahlt, wenn ein Rechner mehrere
Netzwerkschnittstellen hat, oder mehrere Adressen an einer Schnittstelle.
Iperf, nttcp, nuttcp
In diesem Abschnitt stelle ich drei Werkzeuge vor, mit denen ich auf einfache Weise den Netzwerkdurchsatz für TCP und UDP messen kann. Welches der drei ich einsetze, hängt meist von der Verfügbarkeit auf den beteiligten Rechnern ab.
Bei allen drei Werkzeugen benötige ich Zugang zu den Rechnern zwischen denen
ich messen will, zwei Programme kann ich mittels inetd automatisch starten
lassen, so dass ich mich zum Zeitpunkt der Messung nicht anmelden muss.
Rootrechte brauche ich für die Messung nicht.
Für genauere Informationen zu den einzelnen Programmen sind, wie immer, die Handbuchseiten da.
iperf
Bei diesem Programm, dass ich als Client und Server einsetzen kann, erzeugt der Client den Traffic aus dem Hauptspeicher heraus, während der Server die angekommenen Daten verwirft, so dass nur der Durchsatz im Netz und das Handling der Daten im Hauptspeicher gemessen wird.
Ich kann einseitige Messungen machen und anschließend die Client- und Serverrolle tauschen oder zwei Verbindungen in den verschiedenen Richtungen gleichzeitig messen.
Normalerweise dauert eine Messung 10 Sekunden, während derer das Programm versucht, so viele Daten wie möglich zu versenden und an deren Ende es das Ergebnis ausgibt. Alternativ kann ich die Datenmenge vorgeben, so dass die Dauer vom Durchsatz abhängt. Außerdem ist es möglich, die Zeitdauer zu verändern und periodische Berichte ausgeben zu lassen, anstelle eines Berichts am Ende der Übertragung.
Bei UDP kann ich die Datenrate vorgeben und damit das Verhalten des Netzes bei unterschiedlich starker Auslastung untersuchen. Dazu kann ich mir beispielsweise mit Ping die RTT anzeigen lassen und dann das Netz verschieden stark auslasten. Mit TCP kann ich die Datenrate nicht vorgeben, da diese durch die Flusssteuerung automatisch angepasst wird.
nttcp
Das Programm nttcp, das auf dem älteren Programm ttcp basiert, kann die Transferrate für TCP, UDP und UDP-Multicast messen.
Da es die Daten ebenfalls aus Puffern im Hauptspeicher über das Netzwerk sendet, fällt am Rechner nur die Zeit zum Messen und die Zeit im Netzwerkcode des Kernels in’s Gewicht.
Zusätzlich zu den Transferdaten gibt das Programm auch die benötigte CPU-Zeit aus.
Ich kann das Programm via inetd auf einem Rechner starten lassen, so
dass ich mich dort zur Messung nicht anmelden muss.
nuttcp
Dieses Programm, dass auf nttcp basiert, misst ebenfalls den Durchsatz für
TCP, UDP und UDP-Multicast.
Es kann etwa die gleichen Daten wie nttcp anzeigen und außerdem die Verluste
bei UDP.
Wie bei nttcp gibt es einen Sender- und einen Empfängermodus.
Zusätzlich gibt es einen Servermodus, in dem es sowohl senden als auch
empfangen kann.
Dieser ist insbesondere beim Aufruf via inetd nützlich.
Die Ergebnisse werden beim Client angezeigt.
Eine Besonderheit von nuttcp ist, dass es außer
memory-to-memory-Transfer auch disk-to-memory, memory-to-disk und
disk-to-disk messen kann.
Damit ist es möglich Szenarien zu messen, die realistischen Einsatzgebieten
näher kommen.
iproute
Die Programme der iproute-Suite sind moderne Werkzeuge zur Anzeige und Konfiguration von Netzwerkschnittstellen, -routen und der Verkehrskontrolle. Sie bieten gegenüber den Programmen der net-tools-Suite mehr Möglichkeiten.
Die iproute-Suite umfasst unter anderem die folgenden Programme:
- ip
- zum Anzeigen und Konfigurieren von Netzwerkschnittstellen, -adressen, -routen, Policy-Regeln, ARP-Einträgen, IP-Tunneln und Multicast
- ss
- zur Anzeige von Socketstatistiken
- tc
- zur Konfiguration der Netzwerkverkehrskontrolle
- rtmon
- zur Protokollierung der netlink Schnittstelle des Kernels
Weitere und genauere Informationen stehen in den betreffenden Handbuchseiten und der zugehörigen Dokumentation.
ip
Das Program ip dient zum Anzeigen und Manipulieren von Routen, Schnittstellen, Policy-Routing und Tunneln. Es ist das Programm aus der Suite, das ich am häufigsten aufrufe.
Allgemein sieht der Aufruf des Programms wie folgt aus:
ip [ Optionen ] Objekt [ Befehl [ Argumente ] ]
Die Optionen sind allgemeine Modifikatoren, die das Verhalten des Programms
ändern, wie -4 oder -6, welche die Adressfamilie auf
IPv4 oder IPv6 einschränken.
Das Objekt gibt an, worüber ich Informationen wünsche, beziehungsweise, was ich manipulieren will. Mögliche Objekte sind unter anderem:
- link
- Netzwerkschnittstellen
- address
- Protokoll-Adressen an einer Schnittstelle
- neighbour
- ARP- oder NDISC-Einträge
- route
- Einträge in der Kernel-Routingtabelle
- rule
- Regeln in der Policydatenbank
- maddress
- Multicast-Adressen
- mroute
- Multicast-Routingeinträge
- tunnel
- IP-Tunnel
- monitor
- Nachrichten auf der netlink-Schnittstelle des Kernels
Der darauf folgende Befehl gibt die Aktion an, die ich ausführen will. Ihm folgen gegebenenfalls die passenden Argumente. Befehl und Argumente sind spezifisch für die entsprechenden Objekte.
ss
Das Programm ss (socket statistics) liefert Informationen und Statistiken zu Sockets. Ähnliche Informationen kann ich zum Beispiel auch mit netstat bekommen, jedoch habe ich bei ss mehr Möglichkeiten zur Filterung, was mir bei Servern mit vielen Verbindungen zugute kommt.
Der Aufruf ist wie folgt:
ss [ Optionen ] [ Filter ]
Ohne Optionen zeigt ss die verbundenen TCP-Sockets an.
Die wichtigsten Optionen sind unter anderen:
- -a
- um alle Sockets anzuzeigen
- -l
- um nur die Listening Sockets anzuzeigen, diese lässt es sonst aus
- -p
- um die zugehörigen Prozesse anzuzeigen, dafür benötige ich Rootrechte
- -t | -u | -w | -x
- um TCP-, UDP-, Raw- oder Unix-Sockets auszuwählen
Der Filter beim Aufruf von ss hat die allgemeine Form:
[ TCP-Status ] [ Ausdruck ]
Um nach TCP-Status zu filtern, gebe ich das Schlüsselwort state oder
exclude gefolgt von einem der Standard-TCP-Zustandsnamen oder einem
der folgenden an:
- all
- für alle Zustände
- bucket
- für TCP-Minisockets (TIME-WAIT|SYN-RECV)
- big
- für alle außer den Minisockets
- connected
- für verbundene Sockets
- synchronized
- für alle verbundenen Sockets, die nicht im Zustand SYN-SENT sind
Falls weder ein state noch ein exclude Statement vorhanden
ist, gilt die Voreinstellung all bei Option -a und ansonsten
alle außer listening, syn-recv, time-wait und closed.
Mit dem Ausdruck kann ich nach Adressen und Ports filtern.
Weitere Optionen und Informationen zur Filterung gibt es in der Handbuchseite und im Artikel ``SS Utility: Quick Intro’’, den ich bei der Dokumentation des iproute-Pakets finde.
tc
Mit dem Programm tc (traffic control) kann ich die Einstellungen zur Verkehrssteuerung des Kernels ansehen und manipulieren.
Dabei gilt es drei Arten von Objekten zu unterscheiden:
- QDISC
- (queueing discipline) beschreiben das Warteschlangenverhalten, das heißt, wie und in welcher Reihenfolge Datenpakete, die in eine QDISC eingereiht wurden, an den Treiber der Netzwerkkarte zum Senden übergeben werden. Wenn ein Datenpaket gesendet werden soll, wird es zunächst in die für das Interface konfigurierte QDISC eingereiht.
- CLASS
- Klassen können in QDISC enthalten sein und selbst wiederum weitere QDISC enthalten. Datenpakete werden in den inneren QDISC eingereiht. Datenpakete, die an den Netzwerkadapter übergeben werden, können von jeder inneren QDISC kommen. Dadurch, dass bestimmte Klassen vor anderen an die Reihe kommen, wird der Datenverkehr priorisiert.
- FILTER
- entscheiden, welcher Klasse ein Datenpaket bei einem klassenbasierten QDISC zugeordnet wird.
Klassenlose QDISC
Die folgenden Klassenlosen QDISC stehen zur Verfügung:
- fifo
- ist die einfachste Form (First In, First Out). Die QDISC kann auf Paketebene (pfifo) oder Byteebene (bfifo) begrenzt werden.
- pfifo_fast
- ist die Standard-QDISC für Advanced Router Kernel. Diese enthält eine dreireihige Warteschlange, die das TOS-Feld und die Priorität des Datenpakets beachten.
- red
- (Random Early Detection) simuliert eine überlastete Leitung, indem Datenpakete verworfen werden, wenn sich der Durchsatz der konfigurierten Übertragungsrate nähert.
- sfq
- (Stochastic Fairness Queueing) sortiert die wartenden Datenpakete um, so dass jede Sitzung reihum dran ist.
- tbf
- (Token Bucket Filter) ist geeignet, um den Traffic zu einer präzise konfigurierten Datenübertragungsrate zu verlangsamen.
Klassenbasierte QDISC
Die folgenden klassenbasierten QDISC stehen zur Verfügung:
- cbq
- (Class Based Queueing) bildet eine Hierarchie von Klassen, die sich einen Link teilen und kann sowohl priorisieren als auch den Durchsatz begrenzen.
- htb
- (Hierarchy Token Buffer) ermöglicht garantierte Datenübertragungsraten für Klassen und erlaubt die Ausgabe von oberen Grenzen für das Teilen von Datenübertragungsrate zwischen Klassen. Es enthält begrenzende Elemente auf Basis von TBF und kann Klassen priorisieren.
- prio
- wird für Priorisierung ohne Begrenzung der Datenübertragungsrate verwendet.
Theorie
Die Klassen formen einen Baum, bei dem jede Klasse genau einen Vorfahren hat und mehrere Kinder haben kann.
Manche QDISC erlauben zur Laufzeit Klassen hinzuzufügen (CBQ, HTB), andere nicht (PRIO). Erstere können beliebig viele oder auch keine Subklassen haben, in denen die Datenpakete einsortiert werden.
Jede Klasse enthält genau ein Blatt-QDISC (per Default pfifo), welcher durch ein anderes ersetzt werden kann. Diese QDISC kann wiederum andere Klassen enthalten, die zunächst auch nur ein QDISC haben.
Wenn ein Datenpaket in einer klassenbasierten QDISC ankommt, wird es genau einer der enthaltenen Klassen zugeordnet. Sind Filter für eine Klasse definiert, werden diese zuerst für die Klassifizierung herangezogen. Einige QDISC werten auch das TOS-Feld des IP-Headers aus.
Jeder Knoten im Klassenbaum kann seine eigenen Filter haben. Filter in höheren Ebenen können direkt auf niedrigere Klassen verweisen.
Wenn ein Paket nicht klassifiziert werden konnte, geht es in die Blatt-QDISC der Klasse.
Namen
Alle QDISC, Klassen und Filter haben Ids, die automatisch bestimmt oder explizit spezifiziert werden. Diese Ids bestehen aus einer Haupt- und einer Nebennummer, getrennt durch Doppelpunkt.
Eine QDISC, welche Kinder haben kann, bekommt eine Hauptnummer, die ‘Handle’ genannt wird und lässt die Nebennummer als Namensraum für die Klassen. Üblicherweise benennt man QDISC, die Kinder haben, explizit.
Alle Klassen, die zur selben QDISC gehören, teilen sich die gleiche Hauptnummer. Jede hat eine separate Nebennummer, die Class-Id genannt wird und sich auf die QDISC (nicht die Elternklasse) bezieht.
Filter haben eine dreiteilige Filter-Id, die nur bei einer Filter-Hierarchie benötigt wird.
tc Befehle
- add
- Fügt eine QDISC, Klasse oder einen Filter an. Der Vorfahre
(root oder Class-Id) muss angegeben werden. QDISC oder Filter können mit
dem
handleParameter benannt werden, Klassen mitclassid. - remove
- entfernt eine QDISK
- change
- modifiziert eine Einheit am Ort
- replace
- gleichzeitiges
remove/add, der neue Knoten wird gegebenenfalls neu erzeugt - link
- gleichzeitiges
remove/add, der neue Knoten muss bereits existieren.
Weitere Informationen finden sich in der Handbuchseite.
rtmon
Mit dem Programm rtmon kann ich Änderungen an der Routingtabelle des Kernels
über den netlink Socket beobachten. Das Programm kann vor der ersten
Netzwerkkonfiguration, zum Beispiel in einem Init-Script, gestartet werden.
Rtmon schreibt in eine Datei und stellt der Historie der Routingtabelle einen Schnappschuss des Zustandes beim Start des Programms voran. Die Datei kann ich mit dem bereits besprochenen Programm ip auswerten.
Der typische Aufruf sieht in etwa so aus:
# rtmon file /var/log/rtmon.log
Anschließend kann ich die protokollierten Änderungen wie folgt ausgeben lassen:
# ip monitor file /var/log/rtmon.log
Sowohl beim Aufruf von rtmon, als auch bei dem von ip kann ich angeben, an welchen Objekten ich interessiert bin:
- link
- den Netzwerkgeräten
- address
- den Protokolladressen (IPv4, IPv6) an einem Gerät
- route
- den Einträgen der Routingtabelle
- all
- an allem
Weitere Informationen finden sich auch hier in der Handbuchseite.
libtrace und libtrace-tools
Mit libtrace kann ich ähnlich wie mit libpcap eigene Analysewerkzeuge programmieren. Hier will ich aber auf die mitgelieferten libtrace-tools eingehen, mit denen ich Mitschnitte anfertigen und weiter bearbeiten kann.
Ein Vorteil von libtrace ist, dass diese Bibliothek und die damit geschriebenen Werkzeuge mit Paketmitschnitten aus unterschiedlichen Quellen umgehen und die verschiedenen Formate ineinander umwandeln können. Dazu verwendet libtrace sogenannte URI um das Format und die Quelle beziehungsweise das Ziel anzugeben.
Die folgende Tabelle listet einige der unterstützten Formate auf und gibt an, ob libtrace diese schreiben kann.
Unterstützte Formate für Paketmitschnitte
| Format | URI | Read | Write |
|---|---|---|---|
| Live PCAP Schnittstelle | pcapint:$int | Ja | Ja |
| PCAP Trace Datei | pcapfile:$fn | Ja | Ja |
| ERF Trace Datei | erf:$fn | Ja | Ja |
| DAG Gerät | dag:$devloc | Ja | Ja |
| Native Linux interface | int:$int | Ja | Ja |
| Native Linux interface | ring:$int | Ja | Ja |
| (ring buffers) | |||
| Native BSD interface | bpf:$int | Ja | Nein |
| TSH trace file | tsh:$fn | Ja | Nein |
| FR+ trace file | fr+:$fn | Ja | Nein |
| Legacy DAG ATM Trace Datei | legacyatm:$fn | Ja | Nein |
| Legacy DAG POS Trace Date | legacypos:$fn | Ja | Nein |
| Legacy DAG Ethernet Trace | legacyeth:$fn | Ja | Nein |
| Datei | |||
| Legacy DAG NZIX Trace Datei | legacynzix:$fn | Ja | Nein |
| ATM Cell Header Trace Datei | atmhdr:$fn | Ja | Nein |
| RT Network Protocol | rt:$host:$port | Ja | Nein |
Genug der Vorrede, kommen wir zu den Werkzeugen.
traceanon
Mit traceanon kann ich die IP-Adressen von Paketmitschnitten anonymisieren.
Das ist wichtig, wenn ich einen Paketmitschnitt zu einem Problem weiterreichen,
aber möglichst wenig Informationen zur Netzwerkstruktur preisgeben will.
Das Programm traceanon ändert die IP-Header der Datenpakete sowie die in ICMP
eingebetteten IP-Header und repariert die Prüfsummen innerhalb von TCP- und
UDP-Headern.
Es gibt zwei Schemata: bei dem einen ersetzt traceanon einen kompletten
Adressblock durch einen anderen und beim anderen ersetzt es die Adressen mit dem
Cryptopan-Verfahren einzeln.
Wichtig beim Einsatz von traceanon ist, immer im Hinterkopf zu behalten,
dass IP-Adressen auch auf anderem Weg preisgegeben werden können.
So werden IP-Adressen innerhalb von ARP-Paketen nicht anonymisiert und einige
Anwendungsprotokolle wie zum Beispiel HTTP, SMTP, OSPF und andere
Routingprotokolle können in den Anwendungsdaten Informationen über die
beteiligten Netze verraten.
Der Aufruf sieht so aus:
$ traceanon [options] $sourceuri $desturi
Die Beschreibung der Optionen steht in der Handbuchseite.
tracediff
Dieses Werkzeug findet Differenzen zwischen zwei Mitschnitten und gibt diese aus. Dabei wertet es den Inhalt der Framingheader (PCAP oder ERF) nicht aus.
Mit der Option -m $max kann ich die Ausgabe nach $max
Unterschieden abbrechen lassen.
Der Aufruf sieht so aus:
$ tracediff [ -m $maxdiff ] $firsturi $seconduri
Tracediff ist nützlich, wenn ich mehrere Mitschnitte einer Verbindungssitzung an verschiedenen Stellen aufgenommen habe und diese vergleichen will.
tracemerge
Mit diesem Werkzeug kann ich zwei oder mehrere Paketmitschnitte zu einem kombinieren, wobei die Reihenfolge der Pakete beibehalten wird.
Der Aufruf sieht so aus:
$ tracemerge [ options ] $outputuri $inputuri ...
Die Optionen sind in der Handbuchseite beschrieben.
tracepktdump
Mit diesem Programm kann ich Datenpakete in lesbarer Form ausgeben.
Dabei kann ich mit der Option -f $filter die Ausgabe auf bestimmte
Pakete einschränken und mit -c $count die Anzahl der angezeigten
Pakete begrenzen.
Die Ausgabe ist abhängig davon, inwieweit die Protokolle in libtrace bekannt sind und ändert sich folglich von Version zu Version.
Folgender Beispielaufruf mit tracepktdump aus den libtrace-tools Version 3.0.10 soll das verdeutlichen:
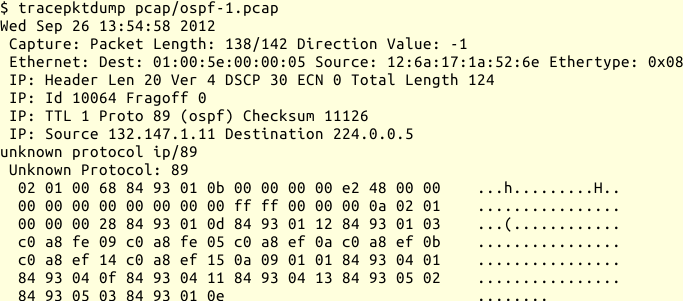
tracepktdump
In dieser Version ist das OSPF-Protokoll in der Bibliothek noch nicht bekannt und wird als Hexdump präsentiert. Die IP- und Ethernet-Header hingegen werden dekodiert und erscheinen nicht im Hexdump.
tracereplay
Dieses Werkzeug spielt einen Paketmitschnitt mit den gleichen Zeitabständen aus einer URI zu einer anderen. Ich kann damit einen Mitschnitt wieder auf das Netz schicken, wenn die zweite URI ein Netzwerkinterface bestimmt, Prüfsummen werden während des Abspielens neu berechnet.
Mit der Option -f $filter kann ich die zurückgespielten Datenpakete
einschränken.
Beim Zurückspielen verwendet tracereplay die Ethernet-Adressen aus
dem Mitschnitt, mit -b kann ich als Ziel-Ethernet-Adresse jedoch die
Broadcast-Adresse angeben.
Der Aufruf sieht so aus:
$ tracereplay [ options ] $inputuri $outputuri
Die Optionen sind in der Handbuchseite beschrieben.
tracereport
Dieses Programm kann eine Reihe von Berichten über die Eigenschaften von
Paketmitschnitten produzieren.
Die Berichte landen in Dateien, deren Name
gleich der langen Option gefolgt vom Suffix .rpt ist.
Folgende Optionen und Reports sind für mich bei der Fehlersuche interessant:
- -e | –error
- erzeugt einen Bericht über Paketfehler (zum Beispiel Prüfsummenfehler, Empfangsfehler).
- -F | –flow
- erzeugt einen Bericht über die Anzahl von Datenflüssen.
- -m | –misc
- liefert einen allgemeinen Bericht (Zeitpunkt des ersten und letzten Paketes, Gesamtzahl der Pakete, …)
- -P | –protocol
- erzeugt einen Bericht über die im Mitschnitt vorkommenden Protokolle der Transportschicht
- -p | –ports
- liefert einen Bericht über die vorkommenden Ports
- -t | –ttl
- berichtet über die TTL der Datenpakete im Mitschnitt
- -n | –nlp
- berichtet über die im Mitschnitt vorkommenden Protokolle der Netzwerkschicht
- -d | –direction
- berichtet, wieviel Traffic in jede Richtung geht
Mehr Optionen und Berichte beschreibt die Handbuchseite.
tracertstats
Mit diesem Programm bekomme ich eine einfache filter- und zeitbasierte Analyse eines Paketmitschnitts. Dabei teilt es den Mitschnitt in Intervalle und gibt für jedes Intervall an, wie viele Datenpakete passend zu den angegebenen Filtern vorkommen.
Die möglichen Optionen sind unter anderen:
- -f $filter
- legt die Filter für die Analyse fest, diese Option kann ich mehrfach angeben
- -i $interval
- bestimmt das zugrunde liegende Zeitraster in Sekunden
- -m
- wenn ich mehrere Paketmitschnitte angebe, sollen diese zusammengefasst werden (merge)
- -o $format
- legt das Ausgabeformat fest (
txt,csv,html)
Weitere Optionen stehen in der Handbuchseite.
tracestats
Dieses Programm gibt ähnliche Analysen wie tracertstats aus, aber jeweils
für den gesamten Paketmitschnitt und nicht für einzelne Zeitintervalle
daraus. Mit der Option -f $filter kann ich auch hier die Pakete
angeben, an denen ich interessiert bin.
Das Programm tracesummary
gibt eine einfache Zusammenfassung für einen Paketmitschnitt an
und ist ein Shellwrapper um tracestats.
tracesplit
Dieses Programm teilt einen Paketmitschnitt in mehrere Dateien auf.
Das kann ich unter anderen mit diesen Optionen beeinflussen:
- -f $filter
- gibt nur die Pakete aus, die zu dem angegebenen Filter passen
- -c $count
- schreibt maximal
$countPakete pro Ausgabedatei. Die Ausgabedateien werden nach dem in der Output-URI angegebenen Basisnamen benannt, an den die Nummer des ersten Paketes in der Datei angehängt wird. - -b $bytes
- schreibt maximal
$bytesBytes in eine Datei - -i $seconds
- startet eine neue Datei aller
$secondsSekunden - -s $unixtime
- beginnt die Ausgabe bei
$unixtime - -e $unixtime
- endet die Ausgabe bei
$unixtime - -m $max
- erzeugt nicht mehr als
$maxAusgabedateien - -S $snaplen
- schneidet die Datenpakete bei
$snaplenab. Ohne diese Angabe wird das komplette Datenpaket geschrieben. - -z $level
- setzt den Kompressionsgrad (0..9)
- -Z $method
- wählt die Kompressionsmethode (
gzip,bzip2,lzoodernone)
Weitere Optionen stehen in der Handbuchseite.
Zwei weitere Werkzeuge sind lediglich Shellwrapper um das Programm
tracesplit:
- traceconvert
- transformiert einen Mitschnitt aus einem Format in ein anderes
- tracefilter
- extrahiert Datenpakete anhand von BPF-Filtern aus einem Mitschnitt
tracetop
Das Programm zeigt die aktivsten n Datenflüsse in einem Intervall an, ähnlich
wie top für Prozesse oder mytop für MySQL-Verbindungen.
Ich kann die Ausgabe mit folgenden Optionen an meine Bedürfnisse anpassen:
- -f $filter
- zählt nur die Pakete, die zu dem Filter passen
- -i $interval
- gibt das Intervall in Sekunden zwischen den Bildschirmaktualisierungen vor (Voreinstellung 2 Sekunden)
- –percent
- zeigt die Bytes und Pakete der Datenflüsse als Anteil vom Gesamtdatenverkehr
- –bits-per-second
- zeigt die Datenübertragungsrate als Bits pro Sekunde an
netcat
Ein weiteres Werkzeug, um schnell eine Netzwerkverbindung herzustellen,
ähnlich wie telnet doch weitaus flexibler, ist netcat.
Damit kann ich nicht nur TCP-, UDP- oder UNIX-Socket-Verbindungen aufbauen,
sondern auch einen einfachen Server für die genannten Protokolle einrichten.
Netcat ist sehr gut in Skripten einsetzbar und kann ein rudimentäres
Port-Scanning für TCP-Ports.
Außerdem, was in manchen Umgebungen wichtig sein kann: netcat kann mit
Proxy-Servern umgehen und darüber Verbindungen herstellen.
Aufruf
Der grundlegende Aufruf ist
$ netcat [ optionen ] $host $port
wenn ich eine Verbindung via TCP oder UDP aufbauen will,
$ netcat [ optionen ] $port
wenn ich auf TCP- oder UDP-Verbindungen warten will, und
$ netcat [ optionen ] $socketpath
wenn ich mit UNIX-Domain-Sockets arbeiten will.
Will ich einen Portscan mit Option -z starten, kann ich statt
eines Ports auch einen Bereich ($port1-$port2) angeben.
Optionen
Einige der wichtigsten Optionen sind:
- -k
- In Verbindung mit der Option
-lwartetnetcatauf weitere Verbindungen, nachdem die erste endet. Ohne diese Option beendet sichnetcatnach der ersten Verbindung. - -l
- Damit wartet
netcatauf eine ankommende Verbindung anstatt selbst eine Verbindung zu öffnen. - -s $addr
- Setzt die Absenderadresse auf
$addr. Das ist nützlich, wenn mein Rechner mehrere Adressen hat. - -U
- verwendet UNIX-Domain-Sockets
- -u
- verwendet UDP statt TCP
- -X $proto
- verwendet Proxy-Protokoll
$proto. Mögliche Werte sind4für SOCKS Version 4,5für SOCKS Version 5 undconnectfür die CONNECT-Methode bei HTTP-Proxies. - -x $addr:$port
- spezifiziert die Adresse und den Port des Proxyservers.
- -z
- weist
netcatan, keine Verbindung aufzubauen, sondern nur nachzuschauen, ob der Port oder Portbereich offen ist. Diese Option kombiniere ich sinnvollerweise mit-vdamit die Ports auch angezeigt werden.
Weitere Optionen finden sich in den Handbuchseiten.
Beispiele
Die folgenden Beispiele sind der Handbuchseite von netcat entnommen.
Client/Server
Für eine einfache Client-Server-Verbindung gebe ich folgendes auf der Serverseite ein:
$ netcat -l 1234
und auf der Clientseite das folgende:
$ netcat host.example.net 1234
um mich mit dem Server zu verbinden.
Mit Option -u verwende ich UDP statt TCP zur Übertragung.
Mit Option -U geht es über UNIX-Domain-Sockets.
Dann verwende ich statt der Portnummer den Pfadnamen zur Socketdatei und
lasse auf Clientseite den Rechnernamen weg.
Die Socketdatei darf beim Start des Serverprozesses noch nicht existieren.
Datentransfer
Um schnell mal eine Datei zu übertragen, erweitere ich das Client/Server Beispiel auf Serverseite wie folgt:
$ netcat -l 1234 > file.out
und auf Clientseite:
$ netcat host.example.net 1234 < file.in
Die Verbindung wird nach erfolgter Datenübertragung automatisch geschlossen. Vertausche ich die spitzen Klammern, wird die Datei vom Server zum Client übertragen.
Einen Server testen
Wenn ich das Plaintext-Protokoll des Servers kenne, kann ich mit netcat auch
komplexe Protokolle bedienen oder testen:
$ netcat -C mail.example.net 25 <<EOT
HELO host.example.net
MAIL FROM:<user@host.example.net>
RCPT TO:<user2@host.example.net>
DATA
Subject: Testmail
Body of email.
.
QUIT
EOT
Mit diesem kurzen Skript kann ich eine E-Mail einspeisen, um einen
Mailserver zu testen.
Das gleiche kann ich auch interaktiv von Hand eingeben.
Die Option -C sorgt dafür, dass netcat im Netz die Kombination CRLF als
Zeilenende sendet, wie es im RFC spezifiziert ist.
Portscanning
Um festzustellen, welche TCP-Ports an einem Rechner erreichbar sind, kann ich
netcat mit den Optionen -z und -v aufrufen:

Portscan mit netcat
netstat
Dieses Programm setze ich auch bei lokalen Problemen auf Linux-Rechnern ein. Daher habe ich es bereits im Kapitel Werkzeuge in Teil 2 dieses Buches beschrieben. Hier gehe ich auf Aspekte ein, die beim Untersuchen von Netzproblemen von Belang sind.
Sockets
Rufe ich netstat ohne Argumente auf, liefert es mir eine Liste der
offenen und aktiven Sockets aller konfigurierten Adressfamilien, das
heisst, der bestehenden Verbindungen.
Meist interessieren mich nicht alle Adressfamilien, sondern nur ganz
bestimmte. Dann kann ich diese zum Beispiel mit der Option
--protocol=$familie einschränken. Für $familie kann ich in
einer durch Komma separierten Liste die folgenden angeben: unix,
inet, ipx, ax25, netrom, ddp. Alternativ
kann ich jeden gewünschten Familiennamen einzeln als Option übergeben:
--unix, --inet, und so weiter.
In diesem Teil der Buches interessiert mich vor allem die Familie
--inet. Diese kann ich weiter eingrenzen. Mit der Option -4
beziehungsweise -6 beschränke ich die Ausgabe auf die entsprechende
Version des Internet Protokolls.
Außerdem verwende ich
- –raw | -w
- wenn ich an Raw-Sockets interessiert bin,
- –tcp | -t
- für TCP-Sockets, und
- –udp | -u
- für UDP-Sockets.
Bin ich nur daran interessiert, ob überhaupt ein Prozess an einem
Socket wartet, verwende ich die Option --listening beziehungsweise
-l. Diese läßt netstat bei der normalen Ausgabe weg.
Will ich sowohl die aktiven als auch die lauschenden Sockets erfassen,
verwende ich die Option --all beziehungsweise -a.
Routen
Wenn ich eher an den Routen als an den Sockets interessiert bin, verwende
ich die Option --route beziehungsweise -r. Damit bekomme ich
die gleiche Ausgabe, wie mit dem Befehl route -e. Auch hier kann ich
mit -4 oder -6 die Protokollversion einschränken.
Füge ich die Option -C hinzu, bekomme ich Informationen aus dem
Routencache, mit der Option -F stattdessen aus der Forwarding
Information Base (der Routentabelle), aber das ist sowieso die
Voreinstellung.
Interfaces
Mit der Option --interfaces oder -i kann ich Informationen
über die Netzgeräte bekommen.
Ein einfaches netstat -i liefert mir in einer übersichtlichen Tabelle
zu jedem aktiven Interface unter anderem die MTU, die Anzahl der gesendeten
und empfangenen Datenpakete sowie die Anzahl der Sende- beziehungsweise
Empfangsfehler.
Kombiniere ich das mit -e, bekomme ich die gleiche Ausgabe wie vom
Programm ifconfig. Kombiniert mit -a zeigt netstat auch Interfaces
an, die nicht aktiviert sind.
Multicast-Gruppen
Die Option --groups beziehungsweise -g liefert mir
Informationen zur Mitgliedschaft des Rechners in Multicast-Gruppen.
Statistiken
Mit der Option --statistics beziehungsweise -s zeigt netstat
zusammengefasste Statistiken für alle Protokolle.
allgemeine Optionen
Abschließen möchte ich diese kleine Vorstellung von netstat mit ein paar allgemeinen Optionen, mit denen ich die Ausgabe modifizieren kann.
Am häufigsten setze ich die Option --numeric, kurz -n ein.
Mit dieser Option zeigt netstat numerische statt symbolischer
Informationen an,
und das beschleunigt insbesondere bei Netzadressen die Anzeige immens,
weil sonst etliche DNS-Anfragen gestellt werden,
bevor die Ausgabe angezeigt werden kann.
Das kann ich auch selektiv mit
--numeric-hosts, --numeric-ports und --numeric-users einstellen.
Mit der Option --verbose oder -v bekomme ich mehr Informationen,
insbesondere zu nicht konfigurierten Adressfamilien.
Ähnliches bietet die Option --extend oder -e, die zusätzliche
Informationen zum Beispiel bei Interfaces liefert.
Gebe ich die Option --continuos oder -c an, bekomme ich die
Informationen aller Sekunde neu ausgegeben.
OpenSSL s_client
OpenSSLs s_client ist das dritte Werkzeug, welches ich zu Verbindungstests
verwende.
Dabei handelt es sich um einen generischen SSL/TLS Client, mit dem ich
verschlüsselte Protokolle wie HTTPS oder SSMTP und die
entsprechenden Server testen kann.
Aufruf
Der grundlegende Aufruf sieht wie folgt aus:
$ openssl s_client -connect $host:$port [ options ]
Optionen
Die folgenden Optionen verwende ich häufiger, weitere sind, wie fast immer, in den Handbuchseiten zu finden.
- -connect $host:$port
- Baut eine SSL- oder TLS-Verbindung zu dem angegebenen Server und Port auf.
- -crlf
- Setzt den Zeilenvorschub des Terminals in CR+LF, wie für einige Protokolle gefordert, um.
- -quiet
- Unterdrückt die Ausgabe der Zertifikat-Informationen.
- -starttls $proto
- sendet die protokollspezifischen Befehle um eine
Verbindung auf TLS umzuschalten.
Momentan werden die folgenden Protokolle unterstützt:
smtp,pop3,imap,ftp.
Bei Problemen mit der Aushandlung des SSL-Protokolls kann ich mit den
Optionen -bugs, -ssl2, -ssl3, -tls, -no_ssl2, … experimentieren.
Details finden sich in der Handbuchseite.
HTTPS-Anfrage
Das folgende Beispiel zeigt eine HTTPS-Anfrage mit openssl:
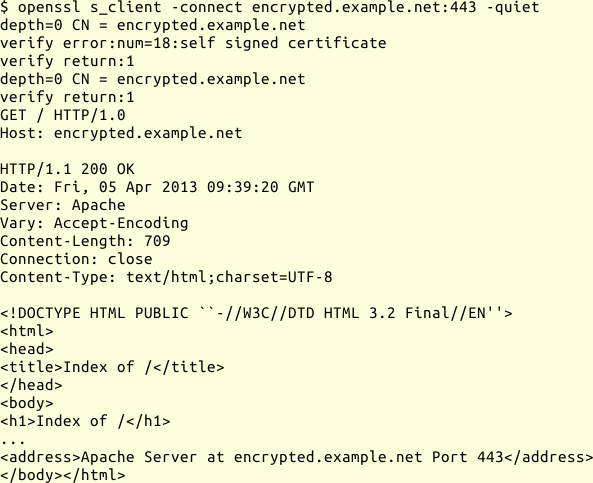
HTTPS-Anfrage mit OpenSSL
Nachdem die verschlüsselte Verbindung
steht, gebe ich meine Anfrage an den Webserver genau so ein, wie ich es mit
netcat bei einem unverschlüsselten Server tun würde und bekomme die Antwort
des Servers angezeigt.
SMTP-SASL-Test
Um die Authentisierung bei SMTP mit SASL zu testen, muss ich mir zunächst den String für die Credentials berechnen. Das PLAIN-SASL-Verfahren ist in RFC4616 beschrieben. Bei diesem sendet der Client einen String mit folgendem Aufbau an den Server.
authzid \0 authcid \0 passwd
Dabei ist
- authzid
- die Authorization Id, die Identität, deren Rechte ich nutzen möchte.
- authcid
- die Authentication Id, die Identität, als die ich mich anmelde.
- passwd
- das Passwort
Der Server überprüft die Gültigkeit von authcid und passwd und dann, ob der Client damit die Rechte der authzid ausüben darf.
Da SMTP ein Plaintext-Protokoll ist, wird der String vor dem Senden mit Base64 codiert. Mit Hilfe von Perl kann ich mir diesen String berechnen lassen:
$ perl -MMIME::Base64 \
-e 'print encode_base64("john\0john\0passwd")';
am9obgBqb2huAHBhc3N3ZA==
Dann baue ich eine verschlüsselte Verbindung mit STARTTLS zum Mailserver auf und melde mich an:
$ openssl s_client -connect smtp.example.net:25\
-starttls smtp -quiet
depth=0 CN = smtp.example.net
verify error:num=18:self signed certificate
verify return:1
depth=0 CN = smtp.example.net
verify return:1
250 DSN
EHLO client.example.net
250-smtp.example.net
250-PIPELINING
250-SIZE 10240000
250-VRFY
250-ETRN
250-AUTH PLAIN LOGIN
250-ENHANCEDSTATUSCODES
250-8BITMIME
250 DSN
AUTH PLAIN am9obgBqb2huAHBhc3N3ZA==
235 2.7.0 Authentication successful
QUIT
221 2.0.0 Bye
Die Meldung 235 2.7.0 Authentication successful zeigt mir, dass die
Anmeldung erfolgreich war.
Perl
Für knifflige Probleme, die ich mit den spezialisierten Werkzeugen nicht zu fassen kriege und denen mit einfacher Shell-Programmierung auch nicht beizukommen ist, benötige ich ein Werkzeug, das mächtiger ist als die Shell und universeller als die verschiedenen vorhandenen Spezialprogramme. Für mich ist das die Programmiersprache Perl. Insbesondere durch die vielen verfügbaren Module auf CPAN kann ich damit sehr schnell Speziallösungen für vertrackte Probleme zusammenbauen.
Ich hatte Perl als Werkzeug bereits im Abschnitt zur lokalen Fehlersuche beschrieben. Durch die vielen einfach verfügbaren und meist sehr gut getesteten und dokumentierten Module auf CPAN ist Perl für mich auch bei Netzwerkproblemen ein unentbehrliches Werkzeug für die Fehlersuche.
Das Perl Kochbuch [CT2000] hatte ich bereits erwähnt. Mit dessen Hilfe und den darin beschriebenen Modulen von CPAN war es mir möglich, in sehr kurzer Zeit ein spezielles Testprogramm für ein Timing-Problem bei einem Webservice zu schreiben.
HTTP Injector
Vor einiger Zeit hatte ich ein Problem, bei dem 502-Fehler eines Webservice von der Zeit, in der die Anfrage gesendet wurde, abhängig waren. Der Betreiber des Webservices war nicht kooperativ und um das Problem zu verifizieren benötigte ich die Möglichkeit HTTP-Anfragen gezielt zu verzögern.
Mit Hilfe des Kochbuches kam ich zu folgendem kurzen Programm:
http-injector.pl
1 #!/usr/bin/perl
2 use Getopt::Long;
3 use IO::Socket;
4 use Time::HiRes qw(sleep);
5
6 my %opt = ( delay => 0 );
7
8 GetOptions( \%opt, 'delay=i');
9
10 my $serv = shift;
11 my $port = shift || 80;
12
13 my $sock = IO::Socket::INET->new(PeerAddr => $serv,
14 PeerPort => $port,
15 Proto => 'tcp');
16
17 my @in = <>;
18 my $del = $opt{delay} / ( 1.0 + scalar @in );
19 foreach (@in) {
20 s/[\r\n]+$//;
21 sleep $del;
22 print $sock $_, "\r\n";
23 }
24 sleep $del;
25 print $sock "\r\n";
26
27 while (my $line = <$sock>) {
28 print $line;
29 }
In den Zeilen 2-4 lädt das Skript die benötigten Module. Die hier verwendeten sind Core-Module, das heißt bei der Installation von Perl automatisch mit installiert.
Getopt::Long- ist für die Verarbeitung der Kommandozeilenoptionen und sichert ab,
dass ich mit
--delayeinen Integerwert angebe. IO::Socket- stellt die Socketfunktionalität bereit, so dass ich diesen Socket wie eine Datei verwenden kann.
Time::HiRes- stellt mir eine verbesserte
sleep()Funktion bereit, die mit Gleitkommazahlen zurechtkommt und Sekundenbruchteile schlafen kann.
In Zeile 6 stellt es die Option --delay auf den Wert 0 ein, falls
diese nicht explizit in der Kommandozeile angegeben wird.
In Zeile 8 werden die Optionen eingelesen.
Zeile 10 und 11 entnehmen den Server und gegebenenfalls den Port der Kommandozeile und in Zeile 13 öffnet es mit diesen Angaben den Socket.
In Zeile 17 liest das Skript die gesamte Eingabe in ein Array ein. Die benötigt es, weil es die Anzahl der Zeilen wissen muss, um die einzelnen Zeilen jeweils nach einem Bruchteil der Gesamtverzögerung senden zu können.
In den Zeilen 19-24 schließlich bereitet es die Zeilenenden auf und sendet die modifizierten Zeilen verzögert über den Socket.
In Zeile 25 schickt es die abschließende Leerzeile, nach der der Server antwortet.
In den Zeilen 27-29 liest das Skript die Antwort des Servers vom Socket und schreibt sie zur Standardausgabe.
Dieses Skript kann ich nun wie folgt aufrufen:
$ time ./http-injector.pl --delay 5 localhost 80 \
< request \
> reply
real 0m5.072s
user 0m0.056s
sys 0m0.012s
Dabei steht in der Datei request die HTTP-Anfrage, die ich an den Server sende. Nach fünf Sekunden ist die Anfrage beim Server, und die Antwort landet in der Datei reply.
Mit diesem Skript konnte ich nachweisen, dass dieselbe Anfrage einen Fehler lieferte, wenn sie mehr als drei Sekunden zur Übertragung brauchte und fehlerfrei beantwortet wurde, wenn sie weniger als drei Sekunden brauchte. Danach fand der Betreiber des Webservice die Stelle, an der der Timeout zu kurz eingestellt war und das Problem konnte aus der Welt geschafft werden.
ping
Eines der grundlegenden und vielseitigsten Werkzeuge für das Netzwerk-Troubleshooting ist Ping. Mit diesem Programm kann ich:
- testen, ob eine Maschine erreichbar ist,
- sehen, wie lange ein Paketaustausch dauert,
- analysieren, welche Datenübertragungsrate die Verbindung zu einem Rechner hat,
- die Performance des Netzwerkes einschätzen,
- eine hohe Netzlast für andere Tests erzeugen.
Natürlich sind alle mit Ping gewonnenen Erkenntnisse mit einer Prise Salz zu nehmen.
In [Sloan2001] beschreibt der Autor die Anwendung von Ping beim Netzwerk-Troubleshooting sehr gut und ausführlich.
Die wichtigsten Kommandozeilenoptionen von ping sind:
- -c $count
- um die Anzahl der gesendeten Datenpakete zu begrenzen,
- -i $interval
- um den zeitlichen Abstand in Sekunden zwischen den einzelnen Paketen vorzugeben, die Voreinstellung ist eine Sekunde
- -s $size
- um die Größe der Datenpakete in Bytes vorzugeben, die Voreinstellung ist 56, hinzu kommen immer 8 Byte für den ICMP-Header
- -n
- um die Auflösung von Hostnamen abzuschalten
- -q
- um die Ausgabe der einzelnen Zeiten abzuschalten, die Statistikinformationen am Ende werden trotzdem ausgegeben
- -f
- um die Ping-Pakete so schnell wie möglich zu senden und dadurch eine
möglichst hohe Netzlast zu erzeugen.
Diese Option sowie die Option
-imit Zeiten unter 0,2 Sekunden benötigen Superuserrechte. Um die Daten mit maximaler Geschwindigkeit zu senden, kombiniere ich diese Option mit-l. - -l $count
- um die Anzahl der Pakete vorzugeben, die
pingsendet, ohne auf Antwort zu warten. Für mehr als drei Pakete benötige ich Superuserrechte.
Daneben gibt es sehr viele weitere Optionen, die ich seltener verwende und deren genaue Auswirkungen ich nötigenfalls aus den Handbuchseiten erschließe.
Verbindungstest
Das ist der einfachste Test, den ich mit Ping ausführen kann. Ich gebe
$ ping $rechnername
ein und bekomme heraus, ob die betreffende Maschine erreichbar ist, ob also Antwortpakete von dort zurück kommen. Manche Versionen des Programms begnügen sich hier mit der einmaligen Ausgabe:
$rechnername is alive
Moderne Versionen zeigen nach Beendigung des Programms (nötigenfalls durch
Abbruch mit <CTRL>-C) die Paketlaufzeiten und einige Statistiken an.
Restriktive Firewalleinstellungen können das Testen der Verbindung mit Ping verhindern. Bei etlichen Rechnern habe ich erlebt, dass diese nach der Installation zwar am Netzverkehr teilnehmen konnten, aber selbst nicht auf ICMP-Hello-Pakete antworteten. Das ist, aus meiner Sicht, eine Überreaktion auf die Tatsache, das einige DoS-Angriffe das ICMP-Protokoll und insbesondere ICMP-Hello verwendet haben.
Man kann nicht jedem vorschreiben, was er in seinem Netzwerk erlaubt und was nicht. Auf jeden Fall empfehle ich, sachlich einen möglichen oder eingebildeten Gewinn an Sicherheit gegenüber der Erschwernis bei der Netzwerkdiagnose abzuwägen.
Netzwerkperformancemessungen
Ein weiteres Anwendungsgebiet sind Performancemessungen im Netzwerk. Am einfachsten geht die Bestimmung der Paketlaufzeit zu einem entfernten Rechner und zurück, denn diese gibt Ping selbst aus. Aber auch die Datenübertragungsrate kann ich mit Ping bestimmen, sowie Netzwerklast für Lastmessungen erzeugen. Dazu suche ich mir einen Zeitpunkt aus, zu dem das Netz wenig belastet ist.
Probleme mit Ping
Einige Dinge gilt es zu beachten, wenn ich Ping beim Troubleshooting einsetze.
Zunächst arbeitet Ping nicht im luftleeren Raum, sondern hängt vom Funktionieren anderer Netzwerkelemente ab. Arbeite ich mit Hostnamen statt IP-Adressen, dann muss DNS funktionieren, oder die Namen müssen via /etc/hosts auflösbar sein.
Dann muss die Ethernet-Adresse des Zielrechners oder Routers aufgelöst werden können. Dazu muss ich sicherstellen, dass das ARP-Protokoll funktioniert oder statische ARP-Einträge verwenden, und zwar auf beiden Seiten. Oft wird die erste RTT bei einer Messung mit Ping durch das ARP-Protokoll verfälscht. Diesem Problem kann ich begegnen, indem ich grundsätzlich mehrere Ping-Pakete sende und die erste Zeit ignoriere.
Bei der Bestimmung der Datenübertragungsrate eines Links verwende ich ohnehin die niedrigste Zeit, da ist dieses Problem bereits berücksichtigt. Ich muss nur daran denken, immer mehrere gleichartige Ping-Pakete zu senden.
Ein weiteres mögliches Problem ist, dass das korrekte Funktionieren des Netzwerkes von Faktoren abhängen kann, die Ping nicht beeinflussen. So kann zum Beispiel ein kleines Ping-Paket problemlos hindurch gelangen, während größere Datenpakete der Anwendungsprotokolle verworfen werden.
Andererseits kann ICMP administrativ blockiert sein, während Anwendungsprotokolle von der Firewall durchgelassen werden, was zu einem False Negative führen kann. Gerade diese Konstellation trifft man häufig in Netzen, die von paranoiden Administratoren konfiguriert werden oder deren Administratoren die Auswirkungen der betreffenden Sperren nicht in vollem Maße abschätzen können. Ich halte es für sinnvoll, die Argumente für und wieder diese Sperren im Einzelfall zu klären und zu dokumentieren, damit es an dieser Stelle nicht immer wieder zu Diskussionen kommt, weil die Sicherheitseinstellungen das Troubleshooting erschweren. Für eine entsprechende Argumentation ist es notwendig, die möglichen Sicherheitsprobleme und gegebenenfalls alternative Gegenmaßnahmen zu kennen.
Einige mögliche Argumente für ein Sperren von ICMP sind:
- Smurf Attacks
- Ein ICMP-Paket mit gefälschter Absenderadresse wird an die Broadcast-Adresse eines Netzes gesendet. Der Rechner, dem die gefälschte Absenderadresse gehört, bekommt von allen Rechnern des Netzsegments eine Antwort. Zur Abhilfe kann man Pakete an Netz-Broadcast-Adressen am Router ausfiltern. Damit schränkt man diesen Angriff auf das lokale Netz ein. In diesem sollte es möglich sein, den Verursacher zu ermitteln.
- Ping of Death
- Es gab Betriebssysteme, die mit übergroßen ICMP-Paketen nicht umgehen und dadurch außer Betrieb genommen werden konnten. Dieses Problem sollte in allen aktuellen Betriebssystemen behoben sein. Notfalls kann man fragmentierte ICMP-Pakete sperren.
- Auskundschaften des Netzes
- Mit ICMP ist es möglich, die Adressen der Rechner in einem IPv4-Netz zu ermitteln. Hier ist zu bedenken, ob das wirklich ein Problem darstellt.
- Unerwünschter Traffic
- Durch ICMP, insbesondere Floodping, kann unnötiger unerwünschter Traffic erzeugt werden, der legitimen Datenverkehr behindert. Hier kann ich das Problem, mit Rate-Limiting am Router eindämmen.
Wenn Ping nicht komplett blockiert wird, ist es möglich, dass das Protokoll eine sehr niedrige Priorität am Router bekommt und allein dadurch, insbesondere bei gut ausgelasteten Routern unter den Tisch fällt oder zumindest die RTT stark verfälscht wird.
Bei manchen Routern kann es vorkommen, dass im Fall von NAT die ICMP-Echo-Antwort oder eine ICMP-Unreachable-Nachricht nicht an den anfragenden Host zurück geht.
Interessanterweise kann ich trotz unterdrücktem ICMP zumindest im lokalen Netzsegment herausbekommen, ob eine bestimmte IP-Adresse verwendet wird. Dazu lösche ich den ARP-Cache und schicke dann ein Ping-Paket zur entsprechenden Adresse. Ist danach ein korrekter ARP-Eintrag vorhanden, ist der Host angeschlossen und unterdrückt das ICMP-Echo.
Eines muss ich bei Ping-Tests immer im Hinterkopf behalten: Ping testet nur die Erreichbarkeit einer bestimmten IP-Adresse. Ob die angebotenen Dienste funktionieren und ob überhaupt der richtige Rechner diese Adresse verwendet, muss ich auf anderem Wege herausbekommen.
 |
Sammle Argumente für und wider das Filtern von ICMP in den von dir betreuten Netzen. Dokumentiere die Argumente und mache die dokumentierten Argumente deinen Kollegen zugänglich. |
Quagga
Einige Probleme im Netzwerk lassen sich auf fehlerhafte Routen zurückführen.
Die Routingtabelle des Kernels kann ich mit den Befehlen netstat -rn,
route -n oder ip route show schnell kontrollieren.
Stelle ich dabei eine fehlerhafte Route fest, frage ich mich als nächstes:
woher kommt diese Route?
Bei der Beantwortung dieser Frage kann mir das Programm quagga helfen.
Quagga ist eine Programmsuite, die Protokolldämonen für die Routingprotokolle RIP, OSPF, BGP und ISIS enthält. Die Konfigurationssprache ist derjenigen von Cisco-Routern ähnlich, so dass jemand, der diese Geräte kennt, sich schnell hineinfindet. Beispielsweise lassen sich fast alle Code-Beispiele aus [Malhotra2002] mit Quagga nachvollziehen, obwohl diese für Cisco IOS geschrieben sind.
Ich kann die Protokolldämonen auf drei Arten konfigurieren: via telnet,
über ein
Programm namens vtysh oder durch Editieren der Konfigurationsdateien im
Verzeichnis /etc/quagga/ und anschließenden Neustart der Protokolldämonen.
Interaktive Konfiguration
Bei der Konfiguration via telnet und vtysh habe ich die
Möglichkeit, die interne Hilfefunktion als Gedächtnisstütze heranzuziehen.
Ausserdem werden Syntaxfehler sofort abgewiesen.
Der Befehl list listet alle momentan möglichen Befehle nebst Argument
auf.
Ein ? an beliebiger Stelle zeigt die möglichen Fortsetzungen. Das
heißt, ein Fragezeichen am Zeilenanfang listet alle momentan möglichen
Befehle, ein Fragezeichen nach einem Befehl listet die möglichen nächsten
Argumente.
Befehle muss ich nur soweit ausschreiben, dass sie eindeutig sind.
Das gleiche gilt für die Argumente.
Mit <Ctrl-P> erhalte ich die letzte Zeile, mit <Ctrl-N> die
nächste. An den Anfang der Zeile der Zeile komme ich mit <Ctrl-A>, an
das Ende mit <Ctrl-E>. Ausserdem funktionieren auf neueren Systemen
die Cursortasten und alle anderen Funktionen der libreadline.
Bei der interaktiven Arbeit mit den Protokolldaemonen habe ich drei Modi. Im
ersten, dem Operatormodus, kann ich im wesentlichen nur Informationen über
den aktuellen Zustand und die Routen abfragen. Mit dem Befehl enable
gelange ich in den Administratormodus und mit disable komme ich
wieder zurück.
Im Administratormodus sehe ich mehr Informationen, vor allem kann ich die
Konfiguration ansehen, sichern oder wiederherstellen.
Aus dem Administratormodus komme ich mit dem Befehl configure terminal
in den Konfigurationsmodus und aus diesem mit end oder exit
zurück in den Administratormodus.
Der Befehl exit im Administrator- oder Operatormodus beendet die
Sitzung.
Im Konfigurationsmodus kann ich jeden einzelnen Aspekt der Konfiguration
ändern.
Dabei lassen sich einzelne Befehle zurücknehmen, indem ich sie mit
vorangestelltem no noch einmal eingebe.
Finde ich zum Beispiel eine statische Route in der Konfiguration:
zebra# show running-config
...
ip route $destination $gateway
...
dann kann ich diese wie folgt entfernen:
zebra# config t
zebra(config)# no ip route $destination $gateway
zebra# end
Auf die gleiche Weise bearbeite ich auch ACL. Diese werden oft mit einer
Auffangregel am Ende abgeschlossen.
Füge ich eine neue spezifische Regel an, ist diese nicht aktiv, weil die
Auffangregel nun davor steht.
In diesem Fall entferne ich die Auffangregel mit vorangestelltem no und
füge sie am Ende wieder an.
Protokollierung
Mit den show ... Befehlen kann ich mir den aktuellen Zustand des
Routingprotokolldämons ansehen. Das hilft mir oft schon, den Fehler
einzugrenzen. Suche ich aber nach der Ursache für den Fehler, dann benötige
ich Informationen darüber, wann etwas passiert ist. Dabei helfen mir die
log und debug Befehle. Mit dem log Befehl lege ich
fest, wohin die Routingdämonen protokollieren und mit den debug
Befehlen, was protokolliert wird. Je nach Routingprotokoll und eingestellter
Protokollierung können die Logdateien sehr schnell sehr unübersichtlich
werden. Dann helfen mir ein paar Zeilen Perl-Skript, die relevanten
Informationen herauszusuchen und zusammenzusetzen.
route
Das Programm route ist für die Anzeige und Manipulation von
Routingeinträgen zuständig.
Da ich die gleiche Funktionialität mit dem Befehl ip route und
entsprechenden Optionen erreichen kann, gehe ich hier nicht näher auf
route ein.
Falls das Paket iproute2 auf einen Rechner nicht installiert ist,
verweise ich auf die Handbuchseite von route, die neben der ausführlichen
Erläuterung der Optionen Beispiele für die Verwendung enthält.
Samba, smbclient
Die Programme der Samba-Suite, insbesondere die zum Paket smbclient zusammengefassten, können bei der Fehlersuche in Zusammenhang mit MS Windows Rechnern helfen.
Davon sind vor allem die folgenden bei der Fehlersuche für mich interessant:
- findsmb
- liefert Informationen über Maschinen, die auf SMB Namensanfragen in einem Netz antworten,
- rpcclient
- führt MS-RPC-Funktionen aus,
- smbclient
- ist ein Programm, mit dem ich auf SMB/CIFS-Ressourcen auf Servern, ähnlich FTP, zugreifen kann,
- smbget
- kann, ähnlich
wgetfür HTTP, Dateien mit dem SMB-Protokoll herunterladen, - smbtar
- ist ein Shellskript, mit dem SMB/CIFS-Freigaben direkt auf UNIX Bandlaufwerke gesichert werden können,
- smbtree
- ist eine Art textbasierter SMB Netzwerkbrowser.
findsmb
Das Programm listet die IP Adresse, den NetBIOS-Namen, den Namen der
Arbeitsgruppe, des Betriebssystem und der SMB-Server-Version. Bei einem
lokalen Masterbrowser fügt es ein + hinzu, bei einem Domain
Masterbrowser ein *.
rpcclient
Das Programm wurde ursprünglich entwickelt, um die MS-RPC-Funktionalität in Samba zu testen. Damit kann man auch Windows NT Clients von UNIX-Arbeitsstationen aus administrieren. Es läßt sich gut in Skripten verwenden.
Für nähere Informationen schaue ich in die Handbuchseiten.
smbclient
Mit diesem Client-Programm kann ich auf SMB- oder CIFS-Ressourcen auf
Servern zugreifen.
Das Interface ist ähnlich dem Programm ftp
für den Zugriff auf FTP-Server.
Damit kann ich Dateien vom Server holen, auf dem Server ablegen und Informationen über Verzeichnisse bekommen.
Mit dem Aufruf
$ smbclient -L $hostname -N
kann ich anonym alle Dienste des Servers $hostname abfragen.
smbget
Mit diesem Programm kann ich Dateien von Servern mit dem SMB-Protokoll abholen, ähnlich wie mit dem Programm wget für das HTTP-Protokoll. Die Dateien werden als smb-URL angegeben. Eine smb-URL sieht wie folgt aus:
smb://[[[dom;]usr[:pas]@]host[/share[/path[/file]]]]
Für Informationen zu den möglichen Optionen schaue ich in die Handbuchseite.
smbtree
Dieses Programm gibt eine Baumstruktur als Text aus, die alle bekannten Domains, die Server in diesen Domains und die Freigaben auf diesen Servern auflistet. Das kann in etwa so aussehen:
$ smbtree -N
WORKGROUP
\\HOST1 host1 server (Samba, Ubuntu)
\\HOST1\bilder
\\HOST1\psc HEWLETT-PACKARD OFFICEJET
\\HOST1\IPC$ IPC Service (host1 server (Samba))
\\HOST1\print$ Printer Drivers
\\HOST2 Samba 3.5.6
\\HOST2\public
\\HOST2\share
\\HOST2\IPC$ IPC Service (Samba 3.5.6)
tcpdump
Bei schwierigen Netzwerkproblemen verwende ich - quasi als große Kanone - tcpdump zum Mitschreiben des Datenverkehrs. Dabei setze ich tcpdump vorzugsweise auf Servern, die keine grafische Benutzeroberfläche haben, oder auf Routern/Bridges mit Linux oder BSD als Betriebssystem, ein. Auf Arbeitsstationen mit grafischer Oberfläche bevorzuge ich Wireshark.
Ich verwende tcpdump
- um das Verhalten andere Werkzeuge zu kontrollieren und zu verifizieren. Erhalte ich zum Beispiel via Ping keine Antwort von einer bestimmten IP-Adresse, sehe ich mit tcpdump nach, ob mein Rechner die ICMP-Anfragen überhaupt absendet.
- um das Vorkommen bestimmter Datenpakete zu verifizieren. Zum einen überhaupt, wie im Beispiel mit Ping und zum anderen an verschiedenen Stellen im Netz, um durch Bisektion die Stelle im Netz zu finden, an der der Datenfluß unterbrochen ist.
- um Protokollverhalten zu verifizieren und/oder Protokollfehler nachzuweisen. Das erfordert umfangreiche Kenntnisse der untersuchten Protokolle, die sich in vielen Fällen durch Studium der relevanten RFCs erlangen lassen.
- um Datenmitschnitte für die Auswertung mit Wireshark zu sammeln. Zwar habe ich in Wireshark auch nur die selben Daten zur Verfügung wie in tcpdump, aber bereits die Statistikfunktionen können mir Hinweise auf Netzprobleme geben, die ich mit tcpdump nicht so leicht wahrgenommen hätte. Abgesehen davon ist die Darstellung der einzelnen Protokollschichten bei Wireshark anschaulicher. Alternativ kann ich die libtrace-tools zur Unterstützung der Auswertung heranziehen.
Am häufigsten verwende ich tcpdump zum Mitschneiden von Datenverkehr. Dazu benötige ich Superuserrechte. Je nachdem, wie viele Schnittstellen mein Rechner hat, muss ich diese manchmal explizit angeben. Prinzipiell schalte ich die Namensauflösung ab, wenn ich mir die Datenpakete anzeigen lasse, um Verzögerungen durch DNS-Anfragen zu vermeiden.
Will ich die Daten nicht sofort auswerten, kann ich diese auch in eine Datei schreiben lassen, die ich dann später mit tcpdump, libtrace oder wireshark auswerte. Für die Auswertung der Datei benötige ich keine Superuserrechte sondern nur Leserechte auf die Datei.
Will ich über einen längeren Zeitraum Datenpakete mitschneiden und in Dateien archivieren, kann ich tcpdump anweisen, bei Erreichen einer bestimmten Dateigröße oder alternativ periodisch nach einer bestimmten Zeit mit einer neuen Datei zu beginnen.
Manche IPSEC-Verbindungen kann tcpdump dekodieren, wenn ich den Schlüssel angebe.
Bin ich nur an den Kopfdaten und nicht an den Anwendungsdaten interessiert, kann ich die maximale pro Datenpaket mitgeschnittene Länge vorgeben. Damit erhöht sich gleichzeitig die Verarbeitungsgeschwindigkeit, wenn ich die Daten in eine Datei schreibe. Andererseits können wichtige Informationen verloren gehen, wenn ich die Länge zu kurz wähle.
Kommandozeilenoptionen
Die Optionen, die ich am häufigsten verwende, sind:
- -n
- um die Namensauflösung abzuschalten.
- -l
- um die Daten während des Mitschnitts zu beobachten. Andernfalls puffert tcpdump die Standardausgabe und zeigt die Datenpakete nicht sofort an, wenn sie eintreffen.
- -U
- um den Schreibpuffer beim Schreiben in eine Datei nach jedem
angekommenen Datenpaket zu leeren.
Das ist nützlich, wenn ich die Datei in einem anderen Fenster zur
gleichzeitigen Auswertung geöffnet habe.
Dort verwende ich dann die Option
-l. Die Optionen -U und -l führen allerdings zu einer höheren I/O-Belastung, was ich insbesondere bei Rechnern, die nahe ihrer Leistungsgrenze betrieben werden, beachten muss. - -w $filename
- um in eine Datei zu schreiben.
- -r $filename
- um aus einer Datei zu lesen.
- -i $device
- um das Interface anzugeben, an dem ich mitschreiben will.
Ab einem Kernel der Version 2.2 ist es möglich an allen Interfaces
gleichzeitig mitzuschreiben. Dafür gebe ich als Device
anyan. - -C $filesize
- weist tcpdump an, beim Schreiben in eine Datei
automatisch eine neue Datei zu öffnen, wenn die alte größer als
$filesizeist. An den Dateinamen wird eine fortlaufende Nummer angehängt. - -G $seconds
- um die mit
-wangegebene Datei nach der in Sekunden angegebenen Zeit zu rotieren. Der Name der Datei sollte eine Zeitformatangabe für strftime(3) enthalten, damit sie nicht überschrieben wird. Zum Beispiel bekomme ich mit dump-%H%M.pcap die Stunde und Minute in den Dateinamen, zu der der betreffende Mitschnitt beginnt. - -F $filename
- um den Filterausdruck, der sonst am Ende der Kommandozeile folgt, aus der angegebenen Datei zu lesen.
- -q
- um die ausgegebenen Informationen zu reduzieren, so dass die Ausgabezeilen kürzer werden.
- -v
- um mehr Informationen pro Datenpaket angezeigt zu bekommen.
Ich kann mehrmals
-vangeben, um noch mehr Informationen zu bekommen. - -s $snaplen
- um die Zahl der Bytes pro Datenpaket, die mitgeschrieben werden, zu begrenzen. 0 bedeutet hier keine Begrenzung.
- -W $filecount
- um die Anzahl der Dateien, die mit
-Coder-Gautomatisch erzeugt werden, zu begrenzen. Je nach Kombination von-C,-Gund-Wwerden Dateien überschrieben oder das Programm beendet sich bei Erreichen der Anzahl von Dateien. Details finden sich in der Handbuchseite. - -x | -X
- um die Header und Nutzdaten als Hexadezimal- und ASCII-Werte ausgeben zu lassen.
Filter
Ein wesentlicher Punkt ist die Möglichkeit, zu bestimmen,
welche Datenpakete tcpdump mitschreibt und welche nicht.
Dazu verwende ich Filterausdrücke, die ich am Ende der Kommandozeile anfüge
oder in einer Datei sammele und mit der Option -F $dateiname übergebe.
Detaillierte Informationen zu
den Filtermöglichkeiten von tcpdump oder libpcap im Allgemeinen finden sich
in der Handbuchseite pcap-filter.
In den meisten Fällen hänge ich den Filterausdruck an das Ende der Kommandozeile, weil das schneller geht. Nur bei komplizierten Filtern schreibe ich den Filter vor Benutzung in eine Datei.
Ein Filterausdruck besteht aus einem oder mehreren Primitiven, die über die
Begriffe and, or oder not miteinander kombiniert werden können.
Ein Primitiv besteht aus einer ID, das ist ein Name oder eine Zahl,
der ein oder mehrere Qualifizierer vorangestellt werden. Die Qualifizierer
bestimmen, welche Bedeutung die ID hat.
So kann zum Beispiel die ID smtp
zusammen mit dem Qualifizierer zum einen auf eine Ethernetadresse verweisen
(ether host smtp), auf eine IP-Adresse (host smtp), auf den
TCP-Port 25 (port smtp) oder auf etwas anderes.
Es gibt drei Arten von Qualifizierern, die miteinander kombiniert werden können:
- Typqualifizierer
- geben an, worum es sich bei der ID handelt.
Mögliche Typen sind
host(ein einzelner Rechner),net(ein ganzes Netz, Netznamen können zum Beispiel in /etc/networks definiert werden),port(ein TCP- oder UDP-Port, Portnamen werden in /etc/services definiert) oderportrange(ein Portbereich, zwei Ports verbunden mit Bindestrich). - Richtungsqualifizierer
- geben die Datenübertragungsrichtung zu oder
von der ID an. Mögliche Richtungen sind unter anderem
src,dst,src or dst,src and dst,inbound,outbound. Fehlt der Richtungsqualifizierer, wirdsrc or dstangenommen. - Protokollqualifizierer
- beschränken das Primitiv auf ein bestimmtes
Protokoll. Das können unter anderem
etherfür Ethernet,ipfür IPv4,ip6für IPv6,arp,tcp,udpsein. Protokollqualifizierer können noch weiter unterteilt sein, die Details entnehme ich im Zweifel der Handbuchseite.
Daneben gibt es noch einige spezielle Primitive, wie gateway,
broadcast, less, greater und arithmetische Ausdrücke,
die ich in Filterausdrücken verwenden kann.
Nachfolgend erläutere ich einige Primitive, die ich häufig einsetze:
- src host $h | dst host $h | host $h
- Entweder die Quelladresse oder die Zieladresse oder
mindestens eine von beiden gehört zu Host
$h. - ether src $e | ether dst $e | ether host $e
- Entweder die Ethernet-Quelladresse oder die
-Zieladresse oder mindestens eine von beiden ist
$e. Dabei kann ich$eals sechs durch Doppelpunkt getrennte Hexbytes oder als Name, welcher in /etc/ethers definiert ist, angeben. - gateway $gw
- Die Ethernet-Adresse gehört zu
$gw, aber die IP-Adresse nicht. So kann ich Datenpakete filtern, die über ein bestimmtes Gateway ankommen oder abgehen. Das funktioniert nur, wenn$gwsowohl als IP-Adresse als auch als Ethernet-Adresse aufgelöst werden kann. - src net $n/$l | dst net $n/$l | net $n/$l
- Entweder die Quelladresse oder die Zieladresse oder
mindestens eine von beiden liegt im Netz
$nmit einer Bitmaskenlänge von$l. Es gibt noch andere Primitive, um das auszudrücken, diese Notation funktioniert für IPv4 und IPv6. - src port $p | dst port $p | port $p
- Entweder der Quellport oder der Zielport oder mindestens
einer von beiden ist gleich
$p. Das ist nur gültig für TCP oder UDP. Falls ich$pals Name angebe, muss er in /etc/services definiert sein. - greater $l | less $l
- Die Paketlänge ist größer/gleich
$loder kleiner/gleich$l. Achtung,$list nicht die Größe des angezeigten IP-Pakets sondern inklusive weiterer Protokollheader. Brauche ich das, teste ich die genauen Werte erst an einem einfacheren Filterausdruck. - ip proto $p | ip6 proto $p
- Das Potokoll
$pist eines der in /etc/protocols definierten Protokolle oder die betreffende Nummer, zum Beispiel 1 füricmp, 6 fürtcp, 17 fürudpoder 89 fürospf. Daicmp,tcpundudpSchlüsselwörter sind, muss ich sie hier mit Backslash (\) schützen:\icmp,\tcp,\udp. - ether broadcast | ip broadcast | ether multicast | ip multicast
- Diese Primitive sind wahr, wenn das betreffende Paket ein Ethernet- oder IP-Broadcast oder -Multicastpaket ist.
- icmp | tcp | udp
- Sind Abkürzungen für
ip proto \p or ip6 proto \p, wobeipfür eines der drei Protokolle steht. Das heisst, ich bekomme die entsprechenden Protokolle, unabhängig davon, ob sie via IPv4 oder IPv6 transportiert werden. - $expr $relop $expr
- Damit kann ich gezielt nach einzelnen Protokolloptionen filtern,
vorausgesetzt ich kenne die genauen Positionen.
So filtert zum Beispiel
ip[0] & 0xf != 5alle IPv4 Pakete mit gesetzten Optionen.Damit lassen sich sehr spezielle Filter erzeugen. Es setzt allerdings auch sehr genaue Kenntnis der untersuchten Protokolle voraus.
Weitere Informationen zu Optionen, Filterausdrücken und deren Bedeutungen gibt es in der Handbuchseite.
telnet
Neben ssh ist telnet für mich ein wichtiges Programm für die Fehlersuche im
Netz. Zum einen verwende ich es für den Zugriff auf ältere Router und
Switches, die das SSH-Protokoll nicht anbieten oder für den Zugriff auf die
interaktive Shell der Quagga-Protokolldämonen. Zum anderen setze ich es für
Tests von Anwendungsprotokollen wie SMTP, POP, IMAP, FTP oder HTTP
ein, die mit Plaintext via TCP arbeiten.
Zwar ist beim Testen der Plaintextprotokolle netcat praktischer, aber
gerade auf älteren Rechnern finde ich häufiger telnet als netcat.
Der Vorteil von telnet liegt eindeutig bei den interaktiven Shells, weil
es die Kennworte nicht auf der Konsole ausgibt, so dass sie nicht
durch einfaches Schultersurfen abgeschaut werden können. Außerdem
funktionieren die Cursortasten mit telnet besser.
Ein Nachteil von telnet gegenüber netcat beim Testen der Plaintextprotokolle
ist, dass das Abbrechen einer Verbindung insbesondere mit einer deutschen
Tastatur eher unbequem ist.
Die Escape-Sequenz, mit der ich in den Kommandomodus umschalte, ist hier
ungünstig belegt, so dass ich meist darauf setze, dass die Gegenstelle die
Verbindung abbaut.
Alternativ kann ich beim Aufruf von
telnet mit der Option -e <irgendwas> ein anderes Zeichen für das
Umschalten in den Kommandomodus mitgeben, muss dann aber ein Zeichen
auswählen, dass im Protokoll nicht vorkommt und trotzdem leicht zu erreichen
ist.
traceroute
Mit traceroute untersuche ich Netzwerkpfade.
Außerdem kann ich damit die maximale Datenübertragungsrate der Netzsegmente
bestimmen, wie in Kapitel 12 beschrieben.
Bei Problemen mit der Erreichbarkeit eines Rechners oder Netzwerkes kann ich es dazu verwenden, das letzte erreichbare Netzsegment zu bestimmen um meine nächsten Schritte auf dieses zu fokussieren. Manchmal kann es bereits einen Hinweis auf die Art des Problems geben. Zum Beispiel deuten in der Ausgabe mehrfach auftretende IP-Adressen auf eine Schleife im Routing hin.
Wenn aufgerufen, sendet traceroute Datenpakete zum Zielrechner, deren
IP-time-to-live-Feld (TTL) es zunächst auf 0 setzt und
dann sukzessive erhöht, bis sie den Zielhost erreichen.
Erhält ein Host oder Router ein Datenpaket mit einer TTL von 0,
verwirft er das Datenpaket und schickt an den Absender eine ICMP-Nachricht,
dass die TTL abgelaufen war.
Diese ICMP-Nachricht enthält die ersten Bytes des verworfenen Datenpaketes,
um dem Empfänger die Zuordnung zu erleichtern.
In der ursprünglichen Variante sendet traceroute UDP-Pakete ab einer
bestimmten Portnummer und erhöht beim Senden nicht nur die TTL, sondern
gleichzeitig auch die Portnummer.
Das erleichtert, die zurückkehrenden ICMP-Nachrichten über den Port den
richtigen TTL zuzuordnen.
Damit ist es möglich mehrere Datenpakete mit verschiedenen TTL und Ports
quasi-parallel zu versenden und die Messzeit zu verkürzen.
Wenn eine UDP-Nachricht am Zielhost angekommen ist, sendet dieser keine
ICMP-ttl-exceeded-Nachricht, sondern stattdessen ICMP-port-unreachable, wenn
an dem betreffenden Port kein Prozess lauscht.
Darum ist es wichtig, für traceroute via UDP einen Bereich zu verwenden,
in dem auf dem Zielhost kein UDP-Port in Verwendung ist.
Zwar kann der Zielhost auch an der IP-Adresse erkannt werden, aber gerade bei
multihomed Hosts oder Routern kann das Datenpaket an einem anderen Interface
ankommen und damit die ICMP-Antwort eine andere Absenderadresse haben.
Da Firewalleinstellungen in Netzwerken immer restriktiver werden, gibt es
einige Varianten von traceroute, die auch andere Protokolle verwenden und
mit einem Port auf dem Zielrechner auskommen. So ist es möglich, traceroute
mit ICMP-echo-Paketen (Ping), TCP-Paketen (zum Beispiel Port 25 oder 80)
oder mit nur einem UDP-Port (zum Beispiel 53 oder 123) zu verwenden, wenn
die Firewall für eines dieser Protokolle freigegeben ist.
Zusätzlich zur IP-Adresse der Hops auf dem Weg zum Zielrechner zeigt
traceroute oft noch die RTT zwischen gesendetem Datenpaket und ICMP-Antwort
an, aus der ich Rückschlüsse auf Art und Zustand des betreffenden
Netzsegmentes ziehen kann.
Auch bei traceroute, wie bei allen Werkzeugen, muss ich bei der
Interpretation der Ergebnisse einige Sachen berücksichtigen.
So zeigt zum Beispiel die Reihenfolge der Hops nur, wie die Daten in einer Richtung zum Zeitpunkt der Messung gelaufen sind. Bei Änderungen im Routing kann sich der Weg bereits während der Messung ändern. Und der Rückweg kann ganz anders aussehen, wenn das Routing asymmetrisch ist.
Einige IP-Stacks senden ICMP-unreachable-Nachrichten mit einer TTL, die
gleich der ist, mit der das Datenpaket ankam.
Diese erscheinen dann als Zielhost bei symmetrischem Routing erst bei der
doppelten TTL, also viel weiter weg als sie in Wirklichkeit sind.
Die Hops davor sind dann alle mit * markiert.
Wenn auf dem Weg der Daten zum Zielhost Adressen umgesetzt werden (NAT),
dann gehen die ICMP-Nachrichten nach der NAT an die umgesetzte Adresse und
erreichen vielleicht nicht den Rechner, auf dem ich traceroute
gestartet habe.
Schließlich ist es möglich, dass eine sehr restriktive Firewall die
Traceroute-Pakete einfach stillschweigend verwirft. In diesem Fall kann es
sinnvoll sein, traceroute mit anderen Protokollen zu wiederholen und die
Ergebnisse zu vergleichen.
Abgesehen davon ist es möglich, mit traceroute eine
relativ genaue Karte der erreichbaren Netze zu erstellen.
Da es unterschiedliche Implementierungen von traceroute gibt, deren
Kommandozeilenoptionen zum Teil erheblich voneinander abweichen, verweise
ich auf die Dokumentation des installierten Programmes.
Wireshark
Neben tcpdump und den libtrace-tools arbeite ich oft mit wireshark zur
Auswertung von Paketmitschnitten.
Da dieses Werkzeug mit einer grafischen Benutzeroberfläche daherkommt, habe
ich es auf kaum einem Server installiert, wegen der bequemen
Handhabung verwende ich es aber gern zur Auswertung von Paketmitschnitten auf
meiner Arbeitsstation.
Im Internet finden sich etliche Tutorials zum Einsatz von Wireshark, darum gehe ich hier nur kurz auf die Menüpunkte ein, die ich am häufigsten einsetze.
Analyze > Expert Info Composite
Einen ersten Überblick über einen geladenen oder mit Wireshark erzeugten Paketmitschnitt bekomme ich über den Menüeintrag Analyze > Expert Info Composite. In dem daraufhin geöffneten Fenster sind fünf Panels über die Reiter Errors, Warnings, Notes, Chats und Details zu erreichen. Die ersten vier Panels enthalten Bemerkungen von Wiresharks zu Ereignissen mit der Priorisierung entsprechend dem zugehörigen Reiter. Im Panel Details finde ich noch einmal alle Bemerkungen in der Reihenfolge, in der sie im Paketmitschnitt vorkommen. Praktisch ist, das beim Anklicken einer Notiz das zugehörige Datenpaket im Hauptfenster gleich ausgewählt wird.
Statistics > Conversations
Über den Menüeintrag Statistics > Conversations bekomme ich ebenfalls ein Fenster mit mehreren Panels, die ich über Reiter wie Ethernet, IPv4, IPv6, TCP, UDP, …, jeweils gefolgt von einer Zahl, auswählen kann. Dabei sind nur die Reiter aktiv, für die Wireshark Konversationen, das heisst Datenpakete mit dem entsprechenden Protokoll, identifizieren konnte. Die Zahl gibt die Anzahl der verschiedenen Konversationen an.
Im Panel ist dann eine Liste mit einer Zeile pro Konversation und den zugehörigen Parametern zu sehen. Über das Kontextmenü kann ich die entsprechende Konversation als Displayfilter für das Hauptfenster hinzufügen oder einfärben.
Bei TCP und UDP kann ich auch Follow Stream anwählen, um in einem weiteren Fenster die Nutzdaten der Verbindung zu sehen und zu speichern. Damit komme ich sehr bequem an die Nutzdaten heran.
Statistics > IO Graphs
Über diesen Menüeintrag bekomme ich einen grafischen Überblick über den zeitlichen Ablauf des Datenverkehrs. Hier kann ich mit Filtern einzelne Aspekte farblich hervorheben.
Hauptfenster
Bleibt schließlich die Paketliste im Hauptfenster.
Mit Displayfiltern kann ich die angezeigten Datenpakete einschränken. Außerdem kann ich Zeitreferenzpunkte setzen, für eine Analyse des Zeitverhaltens.
Auch hier habe ich die Möglichkeit, über das Kontextmenü und Follow Stream an die Nutzdaten heranzukommen.
Und vor allem kann ich für jedes Datenpaket die verschiedenen Protokollschichten auf- und zuklappen und brauche die entsprechenden Protokollparameter nicht selbst aus dem Hexdump zu ermitteln.