1. Methoden, Heuristiken und Modelle
Um eine gemeinsame Sprache zu finden, lege ich zunächst kurz dar, was ich in diesem Buch unter Methoden, Heuristiken und Modellen verstehe.
- Methode
- Spreche ich von einer Methode, meine ich ein auf Regeln aufbauendes Verfahren um konkrete Erkenntnisse oder praktische Ergebnisse zu erlangen, ähnlich einem Algorithmus. Eine Methode kann ich nur unter bestimmten Voraussetzungen sinnvoll einsetzen. Sie liefert mir dann jedoch klar definierte Ergebnisse beziehungsweise Erkenntnisse.
- Heuristik
- Das Lexikon online für Psychologie und Pädagogik1
beschreibt eine Heuristik wie folgt:
“Als Heuristik oder heuristisches Vorgehen bezeichnet man in der Psychologie eine einfache Denkstrategie für effizientere Urteile und Problemlösungen, die meist schneller, aber auch fehleranfälliger ist als ein Algorithmus.”
Diese Definition kommt dem recht nahe, wie ich Heuristik in diesem Buch verwende. Im Gegensatz zur Methode bekomme ich keine klar definierten Ergebnisse, sondern bestenfalls Anhaltspunkte, die mir eine Richtung für die weitere Untersuchung anzeigen.
- Modell
- Unter einem Modell verstehe ich ein vereinfachtes Abbild der
Wirklichkeit, dass bestimmte, für die Betrachtung wesentliche Merkmale
korrekt abbildet und andere ignoriert.
Ein und dieselbe Situation kann ich mit verschiedenen Modellen beschreiben.
Welches Modell ich wähle, hängt davon ab, welche Eigenschaften ich
untersuchen will.
Bei der Auswahl oder Gestaltung eines Modells gilt es zwei Gefahren zu vermeiden. Bilde ich ein unwesentliches Merkmal mit ab, dann wird das Modell zu komplex und macht es schwerer die wesentlichen Punkte zu erkennen. Lasse ich wesentlichen Aspekte aus, ist es möglich, dass ich die falschen Schlüsse ziehe.
Entscheidungsbaum
Wenn ich auf ein neues Problem treffe, versuche ich es so schnell wie möglich zu charakterisieren, um die nächsten Schritte zu seiner Behebung herauszufinden. Dabei helfen mir Entscheidungsbäume. Programmierer kennen so etwas auch als Programmablaufplan.
Mein grundlegender Entscheidungsbaum bei der Fehlersuche sieht so aus, wie im folgenden Bild. Grundsätzlich werde ich nur tätig, wenn eine der Fragen mit nein beantwortet wird. Damit decke ich fast alle Probleme ab, lediglich intermittierende Probleme erfasst der Entscheidungsbaum nicht.
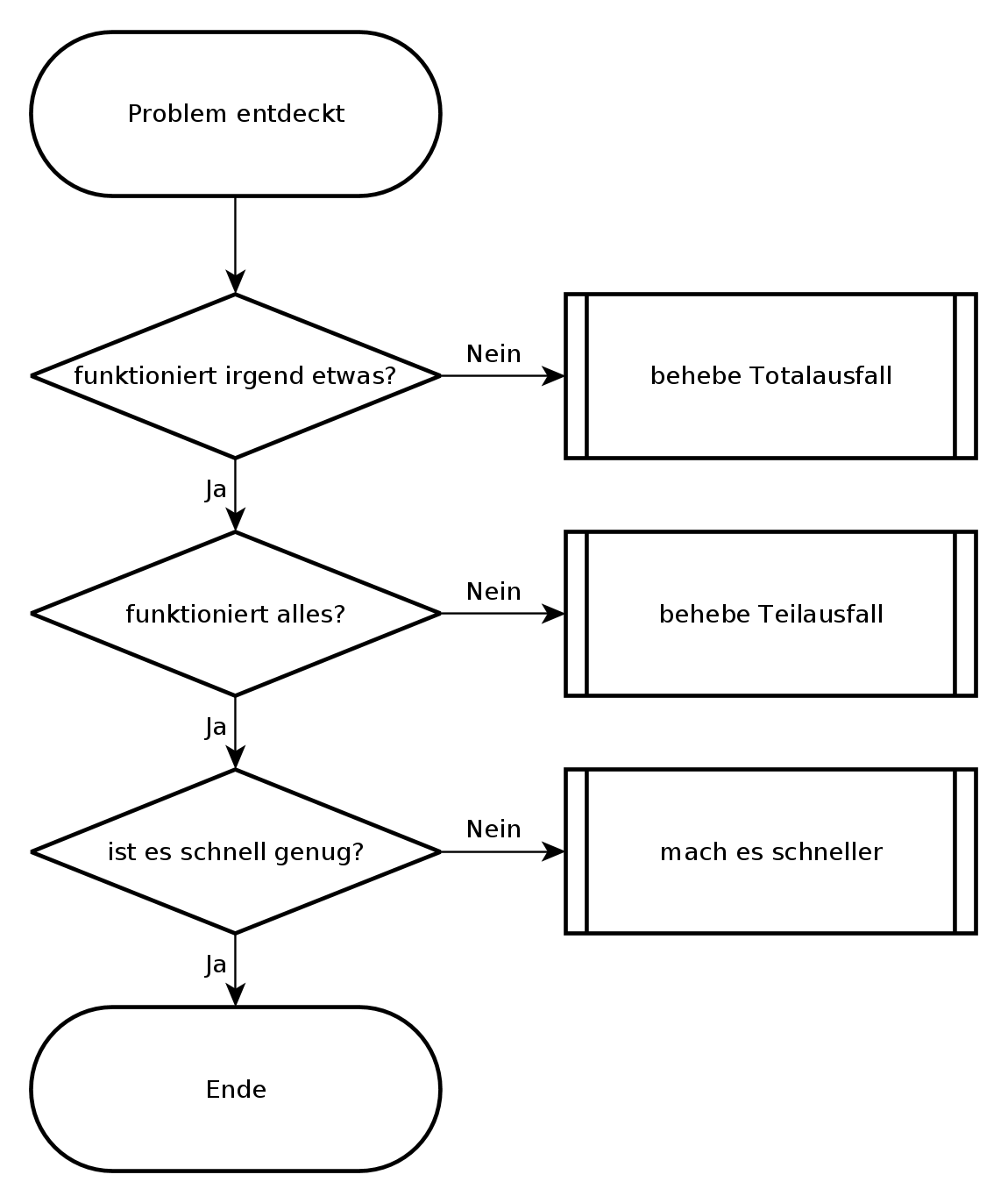
Allgemeiner Entscheidungsbaum
Die erste Frage geht danach, ob überhaupt noch etwas funktioniert oder ob es sich um einen Totalausfall handelt. Diese Frage erscheint vielleicht trivial, aber das ist letztendlich der Zweck eines Entscheidungsbaumes: das die richtigen Fragen im richtigen Moment gestellt werden. Manchmal berichtet ein Anwender, dass eine Funktion eines Programmes nicht funktioniert und irgendwann stellt sich heraus, dass der ganze Rechner eingefroren ist und zwar noch den letzten Bildschirm zeigt, aber weder auf Tastatur, Maus noch Netzwerkzugriffe reagiert. Ein anderes Mal kommt die Meldung, dass das Internet nicht geht (Totalausfall) und auf die Bitte, ein oder zwei andere Websites zu besuchen, stellt sich heraus, dass nur die Startseite des Browsers betroffen ist. Darum versuche ich mit den ersten Fragen herauszufinden, ob es sich um einen Totalausfall handelt, den ich anders behandeln muß als einen Teilausfall.
Liegt kein Totalausfall vor, frage ich als nächstes, ob alle für das Problem relevanten Dienste funktionieren. Es erfordert schon einige Detailkenntnisse zur Problemzone, um zu entscheiden, ob ein Dienst für das Problem relevant ist oder nicht. Im Zweifelsfall kontrolliere ich lieber einen Dienst mehr. Hier geht es vor allem darum, einen Überblick zu bekommen, was funktioniert und was nicht und sich dann über Abhängigkeiten der Teilsysteme an den oder die Urheber des Problems heranzutasten. Dabei gilt es immer im Hinterkopf zu behalten, dass es zwar meist einen konkreten Auslöser für ein Problem gibt, aber oft mehrere Ursachen. Eine Möglichkeit, diese Frage zu beantworten, ist, verschiedene Funktionen einer Software auszuprobieren, verschiedene Netzdienste und Netzziele zu testen. Hierbei kann ein Monitoringsystem wie Nagios gute Dienste leisten, wenn es entsprechend aufgesetzt ist.
Funktionieren alle notwendigen Dienste prinzipiell, kann ich die nächste Frage stellen: ob es schnell genug ist. Diese Frage ist nicht leicht zu beantworten, da jeder seine eigene Vorstellung von schnell genug hat. Gibt es SLA, können diese vielleicht bei der Beantwortung der Frage helfen. Bei nicht interaktiven Aufgaben, wie Datensicherungen oder Batchjobs kann ich die Gesamtlaufzeit betrachten und an Hand dieser entscheiden, ob es schnell genug ist, oder nicht. Bei Dateiübertragungen kann ich an Hand von Datenübertragungsrate, Netzauslastung und Übertragungsdauer überschlagen, ob es Performanceprobleme gibt oder nicht. Bei interaktiven Programmen oder Netzwerkdiensten zählt meist nur die Antwortzeit des Systems, die im Bereich von Sekundenbruchteilen liegen sollte. Komme ich zu dem Schluss, dass es sich um ein Performanceproblem handelt, gehe ich dieses an. Anderenfalls begründe ich, warum es sich meiner Meinung nach um kein Performanceproblem handelt. Dabei kann mir eine Baseline helfen.
Alles in allem habe ich mit den drei Fragen dieses Entscheidungsbaumes eine Richtschnur, die mir hilft, ein Problem herunterzubrechen und mich dem wichtigsten Bereich zu widmen, bevor ich mich in den Details verliere.
Dabei muss ich den Entscheidungsbaum nicht zwangsläufig von oben nach unten verwenden. Wenn mir ein Netzwerk-Performanceproblem gemeldet wird, überzeuge ich mich zunächst davon, dass alle für das Problem relevanten Dienste auch funktionieren. Ich gehe in diesem Fall von unten - dem gemeldeten Performanceproblem - einen Schritt nach oben um sicher zu sein, dass meine folgenden Überlegungen auf einer gesicherten Basis stehen. Zum Beispiel kann ein ausgefallener DNS-Server durch Redundanz zwar kompensiert werden, aber trotzdem zu Verzögerungen durch Timeouts führen, die dann als Performanceproblem wahrgenommen werden.
Außer den drei Hauptfragen gibt es eine vierte Frage, die ich ständig im Hinterkopf behalten muss. Das ist die Frage nach intermittierenden Fehlern und nach der Reproduzierbarkeit des Problems, beziehungsweise meiner Beobachtungen. Habe ich es mit intermittierenden Fehlern zu tun, kann ich nicht mit Sicherheit sagen, ob das Problem wirklich gelöst ist. Nicht einmal, ob meine bisherigen Überlegungen überhaupt zutreffen. Stattdessen hatte ich es vielleicht gerade mit einer komplikationsfreien Zeit zu tun und kurz danach kommt das Problem wieder. Bei intermittierenden Problemen bleibt mir nur, Daten zu sammeln und über Korrelation eine Idee zu bekommen, was das Problem auslösen könnte. Jede Idee, die mir dazu einfällt, muss ich dahingehend prüfen, ob sie das Problem stabil vorhersagbar macht oder nicht.
Bisektion
Die Bisektion, auch Intervallhalbierungsverfahren genannt, verwende ich um eine Fehlerstelle, die in einem Intervall auftritt, schneller zu finden. Das Intervall kann örtlich sein - zum Beispiel bei einer Datenübertragung über mehrere Hops - oder zeitlich - zum Beispiel, wenn sich der Fehler in Logfiles zeigt und ich den Zeitpunkt des ersten Auftretens über viele Logdateien hinweg suche.
Das Verfahren selbst ist sehr einfach. Anstatt das Intervall sequentiell in einer Richtung abzusuchen, halbiere ich es und untersuche von den entstehenden Teilintervallen dasjenige, dessen Grenzen sich unterscheiden. Bei diesem fahre ich mit der Bisektion fort.
Stellen wir uns einen Stapel Papier vor, der auf dem Tisch liegt und auf den ein Tropfen einer sehr aggressiven Flüssigkeit gefallen ist. Um die guten von den beschädigten Blättern zu trennen, kann ich die beschädigten Blätte oben entfernen. Alternativ teile ich den Stapel in der Mitte auf und schaue nach, ob die Blätter unten beschädigt sind. Sind sie beschädigt, werfe ich alle abgehobenen Blätter weg und teile den verbliebenen Stapel wieder bei der Hälfte. Sind sie nicht beschädigt, sichere ich die untere Hälfte und teile die oberen Blätter wieder bei der Hälfte. So fahre ich fort, bis ich zum ersten unbeschädigten Blatt komme. In den meisten Fällen ist dieses Verfahren schneller, als wenn ich von oben nach unten durchgeblättert hätte.
Wenn ich zum Beispiel einen Rechner in einem weit entfernten Netz zwar via Ping erreichen kann, aber nicht mit Port 25, dann kann ich zunächst untersuchen, ob Datenpakete zu Port 25 beim Sender abgehen und ob sie beim Empfänger ankommen. Kann ich die Datenpakete beim Sender nachweisen, aber beim Empfänger nicht, dann suche ich etwa auf der Hälfte der Strecke, ob diese Datenpakete nachzuweisen sind. Je nachdem, ob sie dort auftreten oder nicht, halbiere ich danach die Strecke zum Empfänger oder zum Sender.
Die Bisektion ist nur dann langsamer als die sequentielle Suche, wenn die gesuchte Stelle sich gleich am Anfang des Intervalls befindet.
Performanceanalyse: USE-Methode
Gerade bei komplexen und verteilten Systemen ist es oft schwierig, die richtige Stelle zu finden, die ich mir bei Performanceproblemen genauer ansehen sollte.
Hin und wieder bekomme ich von Kollegen den Rat, bei einem Performanceproblem an dieser oder jener Stelle genauer hinzuschauen, ohne Erklärung warum. Das kann dann die richtige Stelle sein oder auch nicht. Ist es die richtige Stelle, dann vermute ich ein strukturelles Problem, wenn jemand “aus dem Bauch heraus” die Ursache für ein Performanceproblem benennen kann. Ist es die falsche Stelle, habe ich meine Zeit mit aufwendigen Messungen vergeudet.
Habe ich keine a-priori-Informationen, wähle ich die neuralgischen Punkte besser methodisch aus und verschwende dabei keine Zeit.
Dafür eignet sich die USE-Methode, die am besten gleich nach der Problemaufnahme eingesetzt wird. Brendan Gregg beschreibt diese Methode und andere in [Gregg2013]. Der Kern dieser Methode ist, dass ich einige wenige Systemparameter an allen in Frage kommenden Stellen kontrolliere. In einem Satz zusammengefasst lautet die USE-Methode: “Für jede Ressource kontrolliere Auslastung (Utilization), Sättigung (Saturation) und Fehlerereignisse (Errors)”. Diese drei Parameter lassen sich relativ einfach bestimmen, der Knackpunkt liegt bei “jede Ressource”.
Jede Ressource heißt bei einem lokalen Performanceproblem alle physikalischen Systemkomponenten wie CPU, Platten, Bus, Netzwerk und so weiter. Bei virtuellen Systemen muss ich auch das Hostsystem betrachten und bei Netzwerkspeicher das zugehörige Netzwerk und das Speichersystem. Bei Performanceproblemen im Netz muss ich auf allen beteiligten Switches, Routern, Gateways sowie auf den beteiligten Rechnern nachsehen, aber auch auf den Servern, die für diese Verbindung essentielle Dienste anbieten, wie DNS, LDAP oder Datenbankserver.
Der erste Schritt bei der USE-Methode ist daher das Erfassen einer Liste aller beteiligten Ressourcen oder eines Diagramms für die Systemfunktion, das alle beteiligten Ressourcen enthält.
Beim Erfassen der Ressourcen notiere ich gleich die zugehörigen Charakteristika, wie maximale Bandbreite, minimale Latenz. Manchmal zeigt sich bereits beim Eintragen der Charakteristika in das Funktionsdiagramm eine strukturelle Schwäche des Gesamtsystems.
Habe ich alle Ressourcen identifiziert, kontrolliere ich bei allen Auslastung, Sättigung und Fehler.
Dabei meint Auslastung bei einigen Komponenten, wie CPU oder Netzverbindungen, die Prozentzahl der Zeit, die die Ressource in einem gegebenen Intervall verwendet wird und bei anderen, wie RAM oder Plattenplatz, den Anteil der verwendeten Kapazität an der Gesamtkapazität.
Sättigung meint die Arbeit, die in Warteschlangen wartet, während die
Ressource zu 100 Prozent ausgelastet ist.
Bei der CPU ist das die Anzahl der Prozesse, die nicht blockiert sind und
keine Rechenzeit zugeteilt bekommen haben, wie sie der Befehl uptime anzeigt.
Bei RAM ist es der ausgelagerte Hauptspeicher.
Bei Routern und Gateways die Datagramme, die in Queues auf das Versenden
warten.
Fehler meint die Anzahl der Fehlerereignisse, auch wenn die Operation wiederholt wird. Bei RAM fallen darunter die Pagefaults, nach denen eine Speicherseite von der Platte geladen wird. Im Netz zählen dazu verworfene und fehlerhafte Datagramme, auch wenn das Protokoll diese selbstständig wiederholt.
Wichtig ist, ein geeignetes Zeitintervall zu wählen, da kurze Lastspitzen (Bursts) zu einer Sättigung und damit zu Performanceproblemen führen können, die in einem zu großen Intervall durch die Mittelung untergehen.
Wie interpretiere ich die ermittelten Werte?
Bei der Auslastung deuten 100 Prozent meist auf einen Flaschenhals hin. Eine Ausnahme machen Systeme, die für den maximalen Durchsatz ausgelegt sind.
Eine Auslastung ab 60 Prozent kann zu einem Problem werden, weil kurze Lastspitzen zur Sättigung führen können, die in der Mittelung untergeht und weil manche länger dauernden Aktionen nicht unterbrochen werden können, so dass Verzögerungen durch Warteschlangen häufiger werden.
Jeglicher Grad von Sättigung kann ein Problem sein. Er kann als Länge der Warteschlange dargestellt werden oder als Zeit, die in der Warteschlange verbracht wurde.
Gibt es Zähler, die Fehler anzeigen, sind diese es wert, untersucht zu werden. Insbesondere, wenn sie im Laufe der Untersuchung wachsen.
Negative Fälle sind leicht zu erkennen: niedrige Last, keine Sättigung, keine Fehler. Diese kann ich von den weitergehenden Analysen vorerst ausnehmen.
Der Hauptvorteil der USE-Methode ist, dass ich mit relativ geringem Aufwand herausbekomme, auf welche Punkte ich mich bei der Analyse eines Performanceproblems konzentrieren sollte.
Statistische Verfahren, Korrelation
Statistische Verfahren liefern keine Belege für Ursache-Wirkung-Beziehungen. Sie können mir nur helfen, Ansatzpunkte für Hypothesen zu finden, die ich mit gezielten Tests bestätigen oder widerlegen kann. Dabei muss ich mir vorher im klaren sein, ob ein bestimmter Test darauf angelegt ist, eine Hypothese zu widerlegen und damit von der weiteren Betrachtung auszuschließen oder die Hypothese zu bestätigen, so dass ich davon meine weiteren Handlungen leiten lassen kann.
Ein statistisches Verfahren ist die Korrelation. Mit dieser kann ich eine Beziehung zwischen zwei oder mehreren Merkmalen, Ereignissen oder Zuständen beschreiben. Dabei muss ich immer beachten, dass diese Beziehung kausal sein kann aber nicht muss. Im mathematischen Sinne beschreibt die Korrelation einen statistischen Zusammenhang im Gegensatz zur Proportionalität, die einen festes Verhältnis beschreibt.
Will ich den Vierfelder-Korrelationskoeffizient 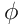 für ein Merkmal und den Fehler ermitteln, stelle ich eine Kontingenztafel auf,
in der ich die gemeinsame Häufigkeit der Merkmale eintrage.
für ein Merkmal und den Fehler ermitteln, stelle ich eine Kontingenztafel auf,
in der ich die gemeinsame Häufigkeit der Merkmale eintrage.
| kein Fehler | Fehler | |
|---|---|---|
| Merkmal trifft zu | A | B |
| Merkmal trifft nicht zu | C | D |
A, B, C, D stehen für die Anzahl der Ereignisse, bei den der Fehler auftrat beziehungsweise nicht auftrat und das Merkmal zutraf oder nicht. Als Werte für A, B, C und D kann ich Zeiträume summieren, oder zu regelmäßigen Zeitpunkten ermitteln, welcher Fall zutrifft und die entsprechende Variable hochzählen.
Der Phi-Koeffizient ermittelt sich dann aus:
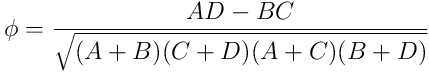
Im einfachsten Fall kann ich eine Korrelation selbst sehen, zum Beispiel, wenn immer die Verbindung zum Netz A wegfällt, sobald ich die Verbindung zum Netz B umschalte. Das sagt zwar nichts aus über die Ursache, es gibt mir aber die Möglichkeit, das Problem kurzfristig temporär aus dem Weg zu schaffen und, wenn die Zeit geeignet ist, das Problem hervorzurufen, um es gründlich zu studieren.
Intermittierende Probleme, die sich dem Zugang entziehen, sind eine Klasse von Problemen, bei welchen Korrelationen hilfreich sind. Bei diesen Problemen hilft mir am Anfang nur, so viele Daten wie möglich über das betroffene Gesamtsystem zu sammeln. Bei der Analyse dieser Daten hilft mir dann die Kovarianzanalyse, das heisst, ich vergleiche jeweils paarweise verschiedene beobachtete Systemvariablen und ermittle den Korrelationskoeffizienten.
Wichtig dabei ist, dass ich immer die zusammengehörigen Daten in Beziehung setze. Da ich den Zusammenhang meist über die Uhrzeit herstelle, sorge ich also entweder im Vorfeld für gleichlaufende Uhren, oder ich muss den Zeitoffset bestimmen und heraus rechnen.
Ein Programm, das sehr hilfreich für die Kovarianzanalyse ist, wurde in [WSA2011] beschrieben.
Wichtig bei Korrelationsanalysen ist, sich vor Augen zu halten, dass unabhängige Merkmale eine Kovarianz nahe 0 haben.
Abkürzungen und Umwege
Im Laufe der Zeit, wenn ich Erfahrungen mit den Systemen gesammelt habe, kann ich bei etlichen Fehlern intuitiv sagen, woran es liegt. Das erspart mir erhebliche Zeit bei der Fehlersuche. Ich muss jedoch immer im Auge behalten, ob meine Annahmen auf einer realen Grundlage beruhen, oder ob mich meine Intuition hier in die Irre führt.
Das heißt, dass ich jedes Mal, wenn ich eine Abkürzung nehme, mich vergewissern muss, dass die Voraussetzungen dafür stimmen.
Abkürzungen
Eine Möglichkeit, die Fehlersuche abzukürzen, ist durch simple Korrelation. Bei der Aufnahme des Fehlers frage ich, wann der Fehler das erste Mal bemerkt wurde und wann es das letzte Mal funktioniert hatte. Im Rahmen der Fehlersuche, schaue ich nach, was am System in diesem Zeitraum geändert wurde und überlege für jede Änderung, ob diese den beschriebenen Fehler hervorrufen könnte. Dazu benötige ich natürlich eine aussagefähige Protokollierung der Änderungen am System. Und der Fehler sollte so schnell wie möglich gemeldet werden, damit der Zeitraum, den ich in Betracht ziehe, nicht zu groß wird.
Eine weitere Abkürzung passiert implizit, wenn ich ähnliche Probleme bereits hatte. Dann konzentriere ich mich automatisch auf die Punkte, die beim letzten Mal zur Lösung geführt hatten. Natürlich muss ich mich fragen, ob die gleichen Voraussetzungen zutreffen.
Umwege
Und damit bin ich schon bei den Umwegen, weil ich, anstatt sofort auf die Lösung zuzustürmen, erst einmal die genauen Umstände prüfe.
Man sagt, Umwege verbessern die Ortskenntnis. Ich interpretiere das so, dass ein Umweg eine Investition in die Zukunft ist, wenn ich damit, neben dem eigentlichen Ergebnis, gleichzeitig eine Annahme über das Gesamtsystem überprüfen kann. Dann ist der Zeitverlust durch den Umweg der Preis für eine Erkenntnis über das System.
Probe und Gegenprobe
Jeder Test, der erfolgreich ist, sollte durch eine geeignete Gegenprobe evaluiert werden, die bestätigt, dass der Test auch versagen kann. Das gleiche gilt für fehlgeschlagene Tests. Diese müssen evaluiert werden, ob sie funktionieren können.
Ist ein Verbindungsversuch auf einem Rechner fehlgeschlagen, versuche ich den gleichen Versuch auf einem anderen Rechner, um nachzuweisen, dass er hätte funktionieren können. Das hat mich schon oft davor bewahrt, einen Netzwerkfehler zu vermuten, wenn lediglich ein Paketfilter die Verbindung unterbunden hatte.
Anti-Methoden
Was sind Anti-Methoden?
Ich habe diesen Begriff zuerst in [Gregg2013] gefunden. Der Autor beschreibt damit Problemlösungsmethoden, die nicht zielgerichtet das Problem lösen, sondern, falls überhaupt, eher zufällig und auf Grund der Umstände und nicht wegen der verwendeten Methode.
Einige dieser Methoden will ich kurz vorstellen, nebst Hinweisen, was man in dem Fall besser machen kann.
Der Anwender von Anti-Methoden verwendet diese teils aus Bequemlichkeit, teils mangels besseren Wissens. Dabei können sie für den, der sie einsetzt, durchaus effektiv sein. Leider sind sie in den seltensten Fällen effizient, das Ergebnis steht oft in einem schlechten Verhältnis zu den insgesamt eingesetzten Ressourcen.
Anti-Methode “Mach andere verantwortlich”
Diese Methode geht so:
- Finde eine System- oder Umgebungskomponente für die Du nicht verantwortlich bist.
- Stelle die Hypothese auf, dass die Ursache des Problems bei dieser Komponente liegt.
- Übergib das Problem an das für diese Komponente verantwortliche Team.
- Wenn bewiesen wurde, dass Du Unrecht hattest, gehe zu Schritt 1.
Anstatt das Problem zu untersuchen, macht man es zu einem Problem anderer Leute und verschwendet die Ressourcen anderer Teams.
Das Hauptproblem bei diesem Ansatz ist, dass der Anwender ohne Analyse der Daten oder gar ganz ohne Daten eine Hypothese aufstellt, die es ihm erlaubt, sich die Arbeit vom Hals zu schaffen.
Wenn man damit konfrontiert wird, ist eine mögliche Gegenstrategie, nach Screenshots oder anderen Protokollen der eingesetzten Werkzeuge zu fragen, welche die aufgestellte Hypothese stützen, um diese jemand anderes für eine zweite Meinung vorzulegen.
Im schlimmsten Fall muss man sich daran setzen und nachweisen, das das Problem nicht von den genannten Komponenten abhängt. Das kann aufwendiger sein, als das eigentliche Problem zu untersuchen.
Anti-Methode “Straßenbeleuchtung”
Bei dieser Methode verhält der Anwender sich wie der Betrunkene, der nachts unter einer Straßenlaterne nach seinem Schlüssel sucht. Darauf angesprochen, ob er diesen überhaupt dort verloren hätte, entgegnet er, dass er den Schlüssel überall verloren haben könne, aber hier nun einmal das beste Licht sei.
Genau so verhält sich der Anwender, der sich bei der Analyse auf die Werkzeuge verläßt, die ihm vertraut sind, die er im Internet oder zufällig findet und der damit nur schaut, ob sich vielleicht etwas sinnfälliges ergibt.
Mehr Werkzeuge kennenzulernen hilft in diesem Fall etwas. Der Erfolg bei der Problemlösung bleibt aber davon abhängig, was man bereits gelernt hat und die Möglichkeit, ein Problem als Chance zu ergreifen, etwas neues zu lernen, wird selten genutzt.
Besser als diese Methode ist, das Problem nicht aus dem Blickwinkel der Werkzeuge zu betrachten, die mir zur Verfügung stehen, sondern ausgehend von der gründlichen Problemaufnahme und Analyse aller beteiligten Systemkomponenten die richtigen Fragen zu stellen. Das kann dazu führen, dass ich zur Beantwortung dieser Fragen neue Werkzeuge schaffen muss.