11. Partieller Ausfall des Netzes
Ich spreche von einem Teilausfall im Netz, wenn wenigstens die Grundfunktionen bis OSI-Schicht 4 funktionieren und ich alle Netzsegmente erreichen kann. In diesem Fall kann ich das Netz selbst zur Fehlersuche einsetzen und brauche mir nicht die Schuhsohlen ablaufen, um vor Ort nach dem Rechten zu sehen oder via Telefon zu debuggen.
Was also kennzeichnet einen Teilausfall im Netz?
Da ist zunächst der Ausfall essentieller Dienste im Netz, wie DHCP, DNS, NTP, Kerberos und weiterer. Der Ausfall einiger dieser Dienste kann Auswirkungen haben, die die Kunden als Totalausfall wahrnehmen. Das muss ich bereits bei der Aufnahme des Problems berücksichtigen. Für den Kunden macht es keinen Unterschied, ob er das Netz nicht nutzen kann, weil ein Kabel unterbrochen ist, oder weil sein Rechner keine IP-Adresse zugewiesen bekam. Für mich, der ich den Fehler beseitigen will, ist der Unterschied durchaus von Belang.
Weiterhin betrachte ich als Teilausfall, wenn ich einzelne Rechner oder einzelne Dienste auf bestimmten Rechnern nicht erreichen kann. Im Laufe der Untersuchung wird daraus vielleicht ein Total- oder Teilausfall des Rechners; dann behandle ich das, wie in Teil 2 dieses Buches beschrieben.
Als drittes zähle ich partielle Einschränkungen von funktionierenden Diensten dazu. Darunter verstehe ich zum Beispiel Mengenbeschränkungen beim Upload auf Webserver oder beim Versand von E-Mail, Zugriffsbeschränkungen für einzelne Netzsegmente und ähnliches. Diese lassen sich in vielen Fällen auf die Konfiguration des betreffenden Dienstes zurückführen.
Schließlich besteht die Möglichkeit, dass ein Dienst absichtlich gestört wird. Angriffe von Dritten und deren Abwehr sind jedoch nicht Thema dieses Buches und werden höchstens am Rande behandelt.
Bei der Behebung des Teilausfalls lasse ich mich wieder vom grundlegenden Entscheidungsbaum leiten. Das heißt, ich versuche zuerst festzustellen, ob überhaupt etwas funktioniert, also ob ich den Server, auf dem der Dienst läuft, erreichen kann. Eventuell muss ich hier noch einen Schritt zurück und sehen, ob ich andere Rechner im gleichen Netzsegment erreichen kann. Kann ich den Server erreichen, untersuche ich, ob alles funktioniert. Bekomme ich Kontakt zum Dienst, antwortet er korrekt laut Protokoll? Schließlich untersuche ich, ob der Dienst schnell genug antwortet.
Ausfall essentieller Dienste im Netz
Der Ausfall essentieller Dienste im Netz erscheint, oberflächlich betrachtet, manchmal wie ein Totalausfall. Da oft nur ein Dienst auf einem oder wenigen Servern ausgefallen ist, behandle ich ihn bei der Fehlersuche als Teilausfall im Netz. Wichtig ist für mich, diesen Ausfall eines oder weniger Dienste zu identifizieren und vom Totalausfall des Netzes zu unterscheiden.
Bereits vor dem Ausfall muss ich mir Gedanken machen, wie ich die Auswirkungen dieses Ausfalls lindere und wie ich vorgehe, um den Ausfall zu beheben.
Bei DHCP, einem der ersten Netzdienste, mit dem ein Rechner in Kontakt kommt, hilft nur Redundanz, die Auswirkungen eines Ausfalls zu lindern. Server sollten, wenn sie nicht gerade im Cluster betrieben werden, nicht via DHCP konfiguriert werden. Falls die Arbeitsstationen immer die gleiche Adresse bekommen, sind längere Lease-Zeiten von Vorteil, weil dadurch die Client-Konfiguration länger gültig ist und ich etwas mehr Zeit habe, den Dienst wieder zum Laufen zu bringen, bevor alle Clients ohne Konfiguration da stehen.
Bei DNS hilft ebenfalls Redundanz, diese ist im Dienst bereits vorgesehen. In kleinen Satelliten-Netzen kann ich den Nameserver auf dem Gateway nutzen und für wichtige interne Dienste Einträge in der hosts Datei vorsehen. Denn ich kann davon ausgehen, dass beim Ausfall des DNS oft auch der Internetzugang betroffen ist und mir der DNS sowieso nichts genutzt hätte. Durch die zusätzlichen Einträge in der Datei /etc/hosts kann ich intern weiter arbeiten.
Auch bei NTP hilft Redundanz. Bei Ausfall eines Server kann temporär ein anderer dessen IP-Adresse übernehmen, wenn ich Clientrechner habe, die nur eine Adresse für den Zeitserver verwenden können.
Unabdinglich ist, dass ich die essentiellen Dienste überwache und dieses Überwachungssystem so robust aufsetze, dass es auch dann noch funktioniert, wenn die Dienste ausgefallen sind.
Genauso wichtig ist eine vollständige und aktuelle Dokumentation des Netzes, seiner Topologie und der Dienste. Nach meiner Erfahrung kann die Dokumentation auf lange Sicht nur dann aktuell bleiben, wenn es nur eine Stelle gibt, an der ich die Konfiguration und Dokumentation gleichzeitig ändere und wenn mindestens eine der beiden automatisch generiert wird.
Natürlich muss ich an die Dokumentation im Fehlerfall herankommen. Halte ich diese ausschließlich elektronisch vor, ist eine Kopie auf USB-Stick und/oder auf dem Notfall-Laptop manchmal die letzte Rettung.
Wie erkenne ich den Ausfall eines essentiellen Dienstes?
Diese Frage ist insofern wichtig, als sich dieser Ausfall für den Kunden oft als Totalausfall des Netzes darstellt, während ich ihn bei der Fehlersuche als Teilausfall im Netz behandele. Insbesondere, wenn ich noch keine Hinweise vom Monitoring habe, muss ich den Totalausfall vom Ausfall essentieller Dienste unterscheiden können. Die Aussagen des Kunden führen mich hier möglicherweise in die Irre, wenn ich nicht durch genaue Kenntnis der Netztopologie und der Konfiguration der betroffenen Rechner zu den richtigen Schlüssen komme.
Leider gibt es keinen generellen Weg, der in jedem Fall zur Lösung des Problems führt, da jedes Netz seine Eigenheiten hat und einige Dienste nutzt, andere nicht.
Meldet mir ein Kunde einen Totalausfall des Netzes, so frage ich zunächst danach, ob das Problem nur seinen Rechner betrifft, oder alle Rechner in einem bestimmten Bereich. Betrifft es mehrere Rechner, muss ich entscheiden, ob es sich um ein Problem der unteren Schichten des Netzes handelt, oder ob ein essentieller Dienst ausgefallen ist.
Dazu schaue ich mir als erstes die IP-Konfiguration des betroffenen Rechners an. Ist diese korrekt, bezogen auf das Netzsegment, in dem sich der Rechner befindet, kann ich davon ausgehen, dass der DHCP-Dienst nicht der Auslöser des Problems ist. Dann versuche ich, verschiedene Rechner an verschiedenen Stellen im Netz mit PING zu erreichen. Dabei muss ich immer im Hinterkopf haben, dass manche Rechner nicht auf PING antworten, weil Firewall-Regeln das unterbinden. Vielleicht auch, weil der angefragte Rechner auf Grund von Routingproblemen die Antworten nicht zurückschicken kann. Dadurch, dass ich versuche, verschiedene Rechner von verschiedenen Stellen aus zu erreichen, kann ich einige dieser Möglichkeiten ausschließen.
Funktioniert die Verbindung mittels IP-Adresse, versuche ich als nächstes das gleiche mit Namen statt IP-Adressen, um mich zu vergewissern, dass DNS funktioniert.
Wenn auch dieses funktioniert, prüfe ich als nächstes das Verhalten der Anwendungsprogramme. Da es davon sehr viele gibt, mit den unterschiedlichsten Anforderungen an das Netz, gehe ich hier nicht auf Details ein.
Stelle ich bei meinen Untersuchungen fest, dass ein essentieller Dienst ausgefallen ist, versuche ich Kontakt zu dem betreffenden Rechner aufzunehmen und behandle das Problem weiter wie ein Problem auf einem lokalen Rechner.
Es folgen ein paar Hinweise, falls ich Ausfälle bestimmter Netzdienste vermute.
DHCP
Einen Ausfall eines DHCP-Servers erkenne ich daran, dass die Rechner im betroffenen Netzsegment keine gültige Netzkonfiguration bekommen. Mitunter können die Rechner noch einige Dienste, zum Beispiel Drucker, erreichen, wenn sie via Zero Configuration Networking eine Adresse im Netz 169.254.0.0/16 angenommen haben. Zum Überprüfen ob ein DHCP-Server überhaupt läuft, kann ich zum Beispiel das entsprechende Plugin für Nagios verwenden. Ansonsten schaue ich direkt auf dem Rechner mit dem DHCP-Server in den Protokollen nach.
Falls sich der DHCP-Server in einem anderen Netzsegment befindet wie der betroffene Rechner, muss ich mir unter Umständen auch das DHCP-Relay auf den Gateways zwischen DHCP-Server und Client-Rechner ansehen. Manchmal blockieren Firewall-Regeln diesen Dienst.
DNS
Bei einem Ausfall des DNS funktioniert die Auflösung der Namen zu IP-Adressen nicht und für manche Kunden funktioniert scheinbar gar nichts mehr. Tests mit IP-Adressen zeigen allerdings, dass das Netz als solches funktioniert. Natürlich ist es möglich, dass einzelne Namen noch aufgelöst werden. Diese finde ich dann meist in der Datei /etc/hosts.
Vermutete ich einen Ausfall des DNS, überprüfe ich zwei Dinge am betroffenen
Rechner: welche Nameserver sind konfiguriert und antworten diese auf gezielte
DNS-Anfragen?
Bei gezielten DNS-Anfragen verlasse ich mich nicht auf die Resolver-Bibliothek
des Betriebssystems, sondern gebe direkt an, von welchem Nameserver ich eine
Antwort möchte.
Das kann ich mit den Programmen host, nslookup, dig oder mit busybox
nslookup machen, die folgenden Befehle befragen jeweils den Nameserver unter
IP 192.168.1.254 nach www.example.com:
$ host www.example.com 192.168.1.254
$ nslookup www.example.com 192.168.1.254
$ dig www.example.com @192.168.1.254
$ busybox nslookup www.example.com 192.168.1.254
Stelle ich fest, dass ein falscher Nameserver konfiguriert ist, muss ich die Konfiguration korrigieren. Kommt diese vom DHCP-Server, dann muss ich mir dessen Konfiguration ansehen.
Bekomme ich von keinem Nameserver eine Antwort, überprüfe ich die Nameserver von anderen Rechnern aus und mit anderen Anfragen. Sind die Nameserver an sich in Ordnung, suche ich nach Firewall-Regeln, die das DNS behindern.
NTP
Zeitfehler sind subtil, da die Uhrzeit der Rechner oft nur allmählich auseinander driftet. Bestimmte Dienste, wie zum Beispiel Kerberos für die Authentisierung, tolerieren nur geringe Abweichungen der Systemzeit und funktionieren dann scheinbar ohne ersichtlichen Anlass nicht mehr.
Bei zentraler Protokollierung kann ich Zeitfehler bei einzelnen Rechnern an den Zeitstempeln der Einträge erkennen.
Mit dem Programm ntpq kann ich einen NTP-Dämon befragen. Meist sind diese
jedoch so konfiguriert, dass sie nur von bestimmten Rechnern oder nur von
localhost abgefragt werden können.
Das bedeutet, ich muß mich an diesem Rechner anmelden.
Auf dem betroffenen Client-Rechner kontrolliere ich, welcher Zeitserver konfiguriert ist. Stimmt der konfigurierte Zeitserver nicht, korrigiere ich die Konfiguration oder schaue mir die Konfiguration des DHCP-Servers an, falls dieser den zuständigen NTP-Server mitteilt.
Proxy-Autokonfiguration
Prinzipiell gibt es mehrere Möglichkeiten, die Proxy-Server im Webbrowser einzustellen:
- Von Hand. Das skaliert nicht mehr ab einer bestimmten Anzahl Nutzern oder verschiedenen Proxy-Servern.
- Mit einer URL für eine PAC-Datei. Das skaliert nicht mit der Anzahl der Nutzer.
- Vollautomatisch mit dem WPAD-Protokoll. Das will ich haben, wenn es funktioniert.
PAC-Datei
Die Datei für Proxy Auto Configuration (PAC) ist eine Textdatei, die die
JavaScript-Funktion FindProxyForURL(url, host) definiert.
In den Argumenten url und host liefert der Browser den URL und den
Hostnamen für die Datei, die er herunterladen möchte.
Als Rückgabe erwartet er einen String, der ihm den Proxy nennt oder
“DIRECT”, um die Datei direkt abzuholen.
Diese Funktion könnte zum Beispiel so aussehen:
function FindProxyForURL(url,host) {
return "PROXY proxy.example.com:3128; DIRECT";
}
Die Datei muss auf einem Webserver liegen und von diesem mit dem MIME-Typ
application/x-ns-proxy-autoconfig ausgeliefert werden.
Gängige Namen sind proxy.pac oder wpad.dat.
Letzteren verwendet der Browser bei der Bestimmung des URL dieser Datei via
DNS mit dem WPAD-Protokoll.
Habe ich einen Webserver der diese Datei ausliefert, kann ich deren Funktion durch direkte Konfiguration der URL bei den Proxy-Einstellungen des Browsers überprüfen.
WPAD-Protokoll
Eine Datei zu haben, in der ich zentral festlegen kann, wie die Webbrowser den richtigen Proxy-Server finden, ist erst die halbe Miete. Ich muss auch dafür sorgen, dass die Browser diese Datei finden.
Die zunächst am einfachsten erscheinende Lösung ist, den URL dieser Datei im Browser fest einzutragen. Der Vorteil ist, dass ich keine weitere Infrastruktur dafür vorhalten muss. Nachteile sind zum einen, dass ich den URL bei jedem Browser eintragen muss und zum anderen, dass ich den URL nicht nachträglich ändern kann, ohne wiederum zu jedem Browser zu gehen und sie vor Ort anzupassen. Oder kurz: das skaliert nicht mit der Anzahl der Nutzer.
Zum Glück haben sich andere bereits Gedanken über das Problem gemacht und mit dem WPAD-Protokoll einen Weg geschaffen, mit dem nahezu jeder Webbrowser automatisch seinen Proxy finden kann.
Dazu greift das WPAD-Protokoll auf verschiedene Methoden zurück, je nach Browser und Betriebssystem, auf dem der Browser läuft. Die gängigsten Methoden sind DHCP für Rechner, die auch ihre IP-Adresse via DHCP erhalten haben, und bestimmte DNS-Einträge, die den Hostnamen der URL für die PAC-Datei auf eine konkrete IP-Adresse abbilden.
Bestimmen des URL mit DHCP
In der Option 252 (auto-proxy-config) kann der DHCP-Server einem Client die URL der PAC-Datei in einem String mitteilen.
Diese Methode funktioniert nur auf Rechnern, die DHCP-Client sind, da die Browser selbst keine DHCP-Anfragen versenden. Um diese Option zu verifizieren, schaue ich auf dem Client in der Datei /var/lib/dhcp/dhclient.leases nach. Je nach verwendeter DHCP-Client-Software finde ich die Datei eventuell an anderer Stelle.
Dabei kann ich verschiedenen Clients unterschiedliche URLs zuweisen, indem ich den DHCP-Server unterschiedliche Strings an die verschiedenen Clients senden lasse.
Bestimmen des URL mit DNS
Diese Methode ist auch für Rechner mit statisch vergebener IP-Adresse geeignet, weil der Webbrowser mit der Resolver-Bibliothek problemlos Anfragen via DNS stellen kann, während es schwierig ist, den DHCP-Client-Dämon zu gezielten Anfragen nach bestimmten Optionen zu bewegen.
Der Webbrowser versucht nach dieser Methode die PAC-Datei von einem URL zu laden, bei dem die Datei unter dem Namen wpad.dat im Wurzelverzeichnis des Servers zu finden ist und der Hostname wpad lautet gefolgt von bestimmten Domain-Endungen.
Diese Endungen werden zunächst aus dem Domain-Suffix des FQDN des eigenen Rechners gebildet und dann sukzessive von links verkürzt. Das heißt, der Webbrowser versucht auf dem Rechner pc.branch.example.com nacheinander, bis er Erfolg hat, die folgenden URLs:
- http://wpad.branch.example.com/wpad.dat
- http://wpad.example.com/wpad.dat
- http://wpad.com/wpad.dat
- http://wpad/wpad.dat
Das birgt die Gefahr, dass der Browser aus der Domain wpad.com fremdgesteuert werden kann, wenn ich nicht dafür sorge, dass in meiner Second-Level-Zone ein A oder CNAME Eintrag existiert, der auf einen Webserver mit ebendieser Datei verweist.
Zum Überprüfen kann ich die entsprechenden DNS-Anfragen von Hand eingeben und mit wget oder curl versuchen die Datei ohne Verwendung eines Proxy-Servers zu laden.
Ausfall nicht-essentieller Dienste
Ohne Monitoring bemerke ich den Ausfall eines Dienstes oft erst dann, wenn jemand ihn benutzen will. Das kann sehr lange nach dem Ausfall sein, so dass mir die Korrelation von Ereignissen bei der Suche nach der Ursache wenig hilft. Ein Grund mehr, möglichst alle Dienste automatisch in geeigneten Zeitabständen zu überprüfen.
Doch genug der Vorrede, wie gehe ich vor, wenn ich einen ausgefallenen Netzwerkdienst wieder in Gang bringen will? Dazu muss ich zwei Fragen beantworten:
- Bekomme ich Kontakt zu dem Dienst?
- Antwortet der Dienst, wie erwartet?
Für die erste Frage benötige ich, falls ich keinen Kontakt bekomme, genaue Kenntnis der Netztopologie und der Protokolle, insbesondere der verwendeten TCP- oder UDP-Ports. Ich versuche zunächst Kontakt zu den vom Protokoll verwendeten Ports zu bekommen, funktioniert das nicht, dann zu anderen Ports - 22/tcp für SSH zum Beispiel - oder via PING. Im Fehlerfall versuche ich den Kontakt von verschiedenen Stellen im Netz aus, um den Einfluss von Firewalls oder Routingproblemen auszuschließen. Kann ich den betreffenden Rechner überhaupt nicht erreichen, behandle ich das Problem, wie bei einem Totalausfall des Netzwerks an einem Rechner, und zwar an dem Rechner, auf dem der Dienst laufen soll. Kann ich den Rechner erreichen, aber nicht die Ports, die der ausgefallene Dienst benutzt, melde ich mich am Rechner an und behandle das Problem, wie in Teil 2 beschrieben, als partiellen lokalen Ausfall.
Bekomme ich Kontakt zu dem Dienst, hängt mein weiteres Vorgehen von dem
Dienst und den verwendeten Protokollen ab.
Erlaubt das Clientprogramm erweiterte Möglichkeiten zum Debugging, nutze ich
diese.
Bei Plain-Text-Protokollen, wie HTTP, SMTP und ähnlichen, kann ich
mit telnet oder nc den Server direkt ansprechen und die Antwort auswerten.
Viele Protokolle sind in RFC beschrieben, die ich bei der IETF finden kann,
wie zum Beispiel RFC 5321 für SMTP.
Für die verschlüsselten Pendants dieser Protokolle kann ich mit OpenSSL eine
Verbindung aufbauen:
$ openssl s_client -connect www.example.com:443 -crlf
Für binär kodierte Protokolle, wie DNS, LDAP oder NTP, greife ich auf geeignete Client-Programme zurück. Oft kann ich für Tests auch Monitor-Plugins von Nagios verwenden. In hartnäckigen Fällen hilft mir manchmal ein Perl-Skript, wenn ich ein spezielles Problem untersuchen will. Auf CPAN finde ich meist ein passendes Modul für das verwendete Protokoll.
Zusätzlich zu den Verbindungstests melde ich mich am Server, auf dem der Dienst läuft, an und beobachte die Lognachrichten des Dienstes. Dabei beachte ich auch die Umgebung auf dem Server, wie im Abschnitt über die ersten Minuten auf dem Server in Kapitel sechs beschrieben.
Bei intermittierenden Problemen beachte ich zusätzlich das Verhalten des gesamten Verkehrs im Netzwerk, wenn ich dazu verlässliche Zahlen habe. Außerdem hilft in manchen Fällen, das Timing des Protokolls genauer anzusehen.
Schließlich beziehe ich den Hersteller-Support ein, wenn ich solchen für den betroffenen Dienst zur Verfügung habe. Dabei hilft mir, wenn ich meine bisherigen Analysen für Nachfragen seitens der Supportmitarbeiter gut geordnet habe.
Hinweise zu einigen Plaintext-Protokollen
Obwohl Plaintext-Protokolle scheinbar wertvolle Bandbreite verschwenden, haben sie doch einige unbestreitbare Vorteile.
Neben der einfach zu beschreibenden Darstellung des Protokolls erlaubt die
Verwendung von Plaintext die Emulierung und Beobachtung des Protokolls
mit simplen Hilfsmitteln wie telnet, nc oder dem Menüpunkt
Follow TCP-Stream bei wireshark.
Außerdem ist die Entwicklung von Programmen dafür wesentlich einfacher, weil
man die Ausgaben einfach in eine Textdatei schreiben und in Ruhe mit jedem
beliebigen Editor analysieren kann.
Bei der Fehlersuche kann ich dasselbe Werkzeug für die Analyse der unterschiedlichsten Protokolle verwenden und muss nicht erst die Bedienung und die Optionen für Spezialwerkzeuge lernen, die ich dann nur für genau ein Protokoll verwenden kann.
In den folgenden Abschnitten zeige ich auf, wie ich einige der gängigsten Plaintext-Protokolle bei der Fehlersuche verwende und welche Informationen ich dabei gewinnen kann.
HTTP
Das Hypertext Transfer Protocol ist nahezu überall anzutreffen.
Version 1.1 ist in RFC 2616 beschrieben und Version 1.0 in RFC 1945.
Für die Fehlersuche kann ich die beiden meist gleich behandeln.
Ich kontaktiere den Server mit nc und der Option -C, damit nc als
Zeilenende die Kombination CRLF über das Netz sendet.
Ich sende, nachdem die TCP-Verbindung etabliert ist, einen Befehl (Request genannt) einen URI, der angibt, was ich haben will und die Versionsnummer des Protokolls in der ersten Zeile. Darauf können weitere Kopfzeilen folgen, die mit einer Leerzeile abgeschlossen werden. Ich verwende meist nur Host:, um zu überprüfen, dass der Server die richtigen Seiten ausliefert, wenn er mehrere virtuelle Webserver anbietet. Als letztes folgt eine leere Zeile, die anzeigt, dass keine weitere Kopfzeilen folgen.
$ nc -C localhost 80
GET / HTTP/1.0
Host: localhost
Daraufhin sendet der Server seine Antwort.
Diese enthält in der ersten Zeile die Version des Protokolls
und den Status, dann ebenfalls wieder einige Kopfzeilen und nach einer Leerzeile
die eigentlichen Daten, deren Typ durch die Kopfzeile Content-Type: bestimmt
ist.
HTTP/1.0 200 OK
...
Content-Type: text/html
Last-Modified: Wed, 11 Jun 2014 08:49:03 GMT
Date: Fri, 18 Jul 2014 07:35:36 GMT
<!DOCTYPE html PUBLIC ...
Die möglichen Requests sind in den genannten RFC beschrieben. Ich verwende für meine Tests meist nur GET und HEAD.
Muss ich einen Proxy-Server für HTTP oder HTTPS verwenden, gehe ich genauso vor, ich muß lediglich beim URI die volle URL, also mit Protokoll und Host angeben.
$ nc -C localhost 3128
GET http://www.example.org/ HTTP/1.0
Host: www.example.org
Für verschlüsselte Verbindungen kann ich openssl s_client verwenden.
$ openssl s_client -connect www.example.com:443 -crlf
GET / HTTP/1.0
Host: www.example.com
IMAP
Das Internet Message Access Protocol ist in RFC 3520 beschrieben. Meist will ich nur prüfen, ob der Server läuft, ob ich mich anmelden kann und ob der Server auf die Dateien und Verzeichnisse zugreifen kann. Dazu reicht der folgende kleine Test.
1 $ nc -C imap.example.org 143
2 * OK [CAPABILITY ... STARTTLS] Courier-IMAP ...
3 a1 login $user $pass
4 a1 OK LOGIN Ok.
5 a2 list "" INBOX
6 * LIST (\Marked \HasChildren) "." "INBOX"
7 a2 OK LIST completed
8 a3 logout
9 * BYE Courier-IMAP server shutting down
10 a3 OK LOGOUT completed
Generell stelle ich jedem Befehl einen eindeutigen Bezeichner voran.
Die Antworten des Servers beginnen mit * oder mit diesem Bezeichner,
wenn sie sich auf meinen Befehl beziehen.
Im Beispiel habe ich mich mit $user und $pass angemeldet (Zeile 3),
anschließend eine Liste im aktuellen Kontext ("") der Mailbox INBOX
abgefragt (Zeile 5) und mich schließlich abgemeldet (Zeile 8).
Für verschlüsselte Verbindung verwende ich wieder openssl s_client.
Dieses kann mit Option -starttls imap auch das Umschalten von Plaintext
in die verschlüsselte Verbindung übernehmen.
$ openssl s_client -connect imap.example.org:143 \
-starttls imap -quiet
depth=0 CN = imap.example.org
verify error:num=18:self signed certificate
verify return:1
depth=0 CN = imap.example.org
verify return:1
. OK CAPABILITY completed
a1 login $user $pass
a1 OK LOGIN Ok.
a2 logout
* BYE Courier-IMAP server shutting down
a2 OK LOGOUT completed
Mit wireshark oder tcpdump kann ich mich überzeugen, dass die Verbindung
verschlüsselt ist.
POP3
Das Post Office Protocol - Version 3 ist in RFC 1939 beschrieben. Es ist noch einfacher zu testen als IMAP. Ich verwende es meist um neu eingerichtete Postfächer zu kontrollieren, wenn der Server sowohl IMAP als auch POP3 beherrscht.
1 $ nc pop3.example.org 110
2 +OK Dovecot ready.
3 user $user
4 +OK
5 pass $pass
6 +OK Logged in.
7 list
8 +OK 1 messages:
9 1 1686
10 .
11 quit
12 +OK Logging out.
Ich melde mich an mit Nutzernamen (Zeile 3) und Kennwort (Zeile 5). Anschließend lasse ich alle E-Mails im Postfach auflisten (Zeile 7) und melde mich wieder ab (Zeile 11).
Auch hier kann ich das gleiche wieder verschlüsselt mit openssl s_client
erledigen.
SMTP
Das aktuelle RFC für das Simple Mail Transfer Protocol ist 5321. Damit kann ich einen Mailserver wie folgt testen.
1 $ nc -C smtp 25
2 220 smtp ESMTP Postfix (Debian/GNU)
3 helo $myhostname
4 250 smtp
5 mail from: $sender
6 250 2.1.0 Ok
7 rcpt to: $recipient
8 250 2.1.5 Ok
9 data
10 354 End data with <CR><LF>.<CR><LF>
11 Subject: Test
12
13 Nicht mehr als ein Test.
14 .
15 250 2.0.0 Ok: queued as 82C3D440A5
16 quit
17 221 2.0.0 Bye
In Zeile 3 gebe ich den Hostnamen des Rechners an, von dem aus ich teste,
In Zeile 5 die Absenderadresse, die im Envelope der E-Mail verwendet wird,
also zwischen den Mailservern.
Bei der E-Mail taucht diese als Return-Path: in den Kopfzeilen auf.
In Zeile 7 habe ich den Adressaten angegeben und ab Zeile 11 den eigentlichen
Text der E-Mail. Da die Eingabe mit einen einzelnen . in einer Zeile endet,
muss ich so etwas in der E-Mail selbst durch Voranstellen eines weiteren .
maskieren.
In Zeile 16 beende ich die Sitzung.
Durch Variieren von $myhostname, $sender und $recipient kann ich
einfache Tests machen, ob der Mailserver als SPAM-Relay missbraucht werden
könnte.
Auch hier kann ich mit openssl s_client eine verschlüsselte Verbindung
aufbauen.
Ich kann eine SMTP-Sitzung an beinahe jeder Stelle mit QUIT abbrechen.
Will ich nur wissen, ob sich der Server überhaupt meldet und wie schnell, kann
ich es gleich nach der ersten Meldung des Servers eingeben.
Solange ich nicht mit DATA die Übertragung der eigentlichen Nachricht
eingeleitet habe, wird der Server nicht mehr als ein paar Logzeilen
generieren.
Alle meine Eingaben quittiert der Server mit einer dreistelligen Zahl und etwas erläuterndem Text. Dabei besagt die erste Ziffer, ob die Antwort in Ordnung geht. Insbesondere sind folgende Codes für die Antwort des Servers im RFC festgelegt:
- 2yz
- positive Ausführung, alles in Ordnung soweit
- 3yz
- Zwischenmeldung zur positiven Ausführung
- 4yz
- vorübergehender Fehler, der Client kann es später noch einmal versuchen
- 5yz
- dauerhafte Nichtausführung, der Client braucht die gleiche Anfrage nicht noch einmal versuchen.
Die erste Ziffer interessiert mich bei den Tests von Mailservern am häufigsten. Die zweite Ziffer sagt etwas über die Kategorie der Antwort vom Server und die dritte unterteilt die Bedeutung noch weiter. Falls ich deren Bedeutung wirklich einmal brauche, schlage ich sie im RFC nach.
Mailserver, die im Internet erreichbar sind, werden heutzutage von Skripts automatisch getestet, ob sie sich potentiell zur Versendung von SPAM eignen. Dabei wird eine SMTP-Verbindung von einem fremden Netz aus aufgebaut und versucht eine E-Mail an eine Adresse zu versenden, für die der Server definitiv nicht zuständig ist. Kommt diese E-Mail an, dann wird - je nach dem, wer getestet hat - anschließend SPAM über diesen Server versendet oder er landet gleich auf einer Blacklist. Beides erschwert es hinterher, reguläre E-Mail über diesen Server zu versenden.
 |
Die meisten SMTP-Server treffen bereits anhand von IP-Adresse des Senders,
Absender- und Zieladresse eine Vorentscheidung, ob sie eine E-Mail annehmen
oder nicht.
Wenn Du einen Mailserver betreibst, versuche mit Wie verhält sich der SMTP-Server bei verschiedenen IP-Adressen, verschiedenen Absenderadressen und verschiedenen Zieladressen? |
Sonstige Probleme
Falsche Absenderadresse
Die Diskriminierung von Rechnern anhand ihrer IP-Adresse hat den Vorteil, dass ich Ressourcen spare, weil bestimmte Verbindungen, die ich nicht haben will, gar nicht erst zustande kommen. Ich spare
- Rechenzeit, weil der Prozess, der den teilweise gesperrten Dienst anbietet, nichts tun muss,
- Datenverkehr, weil der Server nicht erst die Verbindung annimmt und dann irgendwann wieder schließt,
- Plattenplatz, weil ich keine Einträge im Log bekomme,
- Zeit, wenn ich die Logs durchsuchen muss.
Alles in allem also eine gute Sache, wenn es richtig funktioniert.
Schief gehen kann das aus den unterschiedlichsten Gründen. Hier betrachte ich den Fall, dass ein Rechner, der eine zugelassene Adresse besitzt, nicht durchkommt, weil er eine andere IP-Adresse benutzt.
Allein das zu erkennen dauert manchmal schon sehr lange, weil es oft nur ein winziger Unterschied in der Absenderadresse ist. Und wenn es scheinbar von einem auf den anderen Tag kommt, rechne ich auch nicht gleich mit so etwas.
Wenn ich mehrere IP-Adressen aus einem Segment auf dieselbe Schnittstelle lege und die Schnittstelle zusätzlich via Hot Plug konfiguriert wird, kann ich nicht vorhersagen, welche IP-Adresse zur primären wird und welche zur sekundären.
Bei vielen Programmen kann ich die Absenderadresse in der Konfiguration
oder beim Aufruf des Programmes vorgeben.
Bei netcat zum Beispiel mit der Option -s $absenderadresse.
Wenn das Programm keine Vorgaben zulässt oder ich aus anderen Gründen keine geben will, muss ich auf anderem Weg dafür sorgen, dass der Rechner die richtige Adresse verwendet.
Eine Möglichkeit ist, die gewünschte Adresse zur primären Adresse zu machen.
Wie das geht hängt von der Linux-Distribution ab und wie bei dieser die
Schnittstellen konfiguriert werden.
Das Programm ip von iproute kennt Argumente, mit denen ich das einstellen
kann.
Es ist jedoch mühsam und fehleranfällig.
Ich muss das unter verschiedenen Konstellationen
testen, bevor ich mich darauf verlassen kann.
Eine andere, flexiblere Möglichkeit besteht darin, die Absenderadresse mit
iptables zu modifizieren.
Solange ich es mit keinem Protokoll zu tun habe, das explizit auf die
IP-Adressen Bezug nimmt (IPSEC ist ein Beispiel dafür), macht diese Lösung
keine Probleme und erlaubt sogar, dass ich zu verschiedenen IP-Adressen oder
Ports Kontakt mit unterschiedlichen Absenderadressen aufnehmen kann.
Der Aufruf von iptables lautet:
iptables -t nat -I POSTROUTING \
-o $dev \
-d $server \
! -s $wanted_ip \
-j SNAT \
--to-source $wanted_ip
Hierbei ist $dev die Schnittstelle, über die das Datagramm gesendet wird,
$server die IP-Adresse des Servers, zu dem es geht und $wanted_ip ist die
gewünschte Absenderadresse.
Die Regel greift bei allen Absenderadressen, die von der gewünschten
abweichen.
Mit weiteren Selektoren kann ich die Regel noch weiter einschränken, zum
Beispiel auf den Port oder nur auf TCP.
Diese Lösung ist flexibel und macht mich unabhängig von der aktuell eingestellten primären IP-Adresse.
Der Nachteil ist die komplexere Konfiguration der Firewall und ein erhöhter Aufwand im Kernel, weil die Adresse in jedem Datagramm, das zur Regel passt, umgeschrieben werden muss.
Mehrere Router im Netzsegment
Dieses Problem hat dazu geführt, dass ich in Netzsegmenten mit Endgeräten, die nicht von mir betreut werden, möglichst vermeide, mehrere Router zu verschiedenen Netzen einzusetzen.
Üblicherweise kennen Arbeitsstationen und Server, die sich nicht an den Routingprotokollen beteiligen, nur ein Gateway in andere Netze. Alle Datagramme, die nicht für das lokale Netzsegment bestimmt sind, werden an dieses Gateway geschickt und von diesem weitergeleitet.
Oft genug habe ich erlebt, dass mal eben ein weiteres Netz über ein zusätzliches Gateway in diesem Netzsegment angeschlossen wird. Abgesehen von möglichen Sicherheitsproblemen schicken die Clients ihre Datagramme für dieses Netz zum Standardgateway.
Das ist an und für sich kein Beinbruch, da das Standardgateway die Datagramme an das richtige Gateway weiterleitet und dem Sender eine ICMP-Nachricht schickt, dass dieser das andere Gateway für dieses Netz verwenden soll.
Dieses Verfahren hat nur einen geringen Overhead und funktioniert in vielen Fällen problemlos. Außer, wenn es nicht funktioniert.
Alle mir bekannten Fälle, in denen dieses Verfahren nicht funktioniert hat, betrafen Rechner mit Microsoft Windows als Betriebssystem. Wobei das Verhalten abhängig war von der Version des Betriebssystems und den Einstellungen des Rechners. Mit moderneren Versionen des Betriebssystems traten häufiger Probleme auf, als mit älteren. Manchmal funktionierte die Verbindung im selben Segment bei einigen Arbeitsstationen und bei anderen nicht, ohne dass der zuständige Administrator herausfinden konnte, warum.
Die genaue Ursache ist mir nicht bekannt, ich vermute, dass die Windows-Firewall die Antwortpakete mit der MAC-Adresse des anderen Gateways nicht akzeptiert. In allen Fällen, bei denen ich dieses Verhalten feststellen konnte, funktionierte die Verbindung zum betreffenden Netz sofort, wenn temporär die Windows-Firewall deaktiviert wurde.
Je nachdem, wie gut der Administrator der betroffenen Rechner ist, und wie dringend die Windows-Firewall in dem Netz benötigt wird, bleibt in manchen Fällen nur, den zweiten Router in einem anderen Netzsegment anzuschließen, so dass alle Datagramme wieder über das Standardgateway gesendet werden können.
Path-MTU
Ein Problem, das zunächst oft falsch interpretiert wird, tritt auf, wenn die automatische Bestimmung der Path-MTU nicht funktioniert. Das kann durch Firewall-Regeln passieren, durch NAT oder durch Probleme beim Routing. In Kombination mit einer reduzierten Path-MTU, zum Beispiel bei VPN- oder PPPoE-Verbindungen (DSL) ergeben sich sehr subtile Fehler.
Ich kann dann Plaintext-Protokolle, wie im vorigen Abschnitt beschrieben, testen und zum Beispiel einen SMTP-Server als völlig in Ordnung identifizieren. Trotzdem kann ein anderer SMTP-Server diesem einige E-Mail nicht zustellen, obwohl mein Test vom selben Rechner aus kein Problem anzeigte.
Beim manuellen Testen des Protokolls entstehen meist nur kleine Datenpakete, die in einem Stück durch alle Netzsegmente gesendet werden können. Das gleiche passiert bei kleinen E-Mails von wenigen hundert Bytes.
Sobald die zu versendende Nachricht jedoch größer ist als die Path-MTU, sendet der Server mindestens ein zu großes Datagramm. Da die ICMP-Unreachable-Nachricht nicht bis zu ihm durchdringt, weiß der Sender nicht, dass das Datagramm nicht ankommt. Auch das Wiederholen des Datagramms hilft hier nicht. Der Empfänger hat alle vorherigen Datagramme bestätigt und nun keine Veranlassung seinerseits etwas zu unternehmen, so dass die Verbindung zum Stillstand kommt. Irgendwann beendet einer der Beteiligten die TCP-Sitzung auf Grund eines Timeouts.
Wenn ich nicht von selbst an dieses mögliche Problem denke, kann ich sehr lange an den falschen Stellen suchen.
Mit ping kann ich testen, ob die Path-MTU geringer ist, als die MTU des
ersten Segments:

ping -n -c1 -Mdo -s 1472 172.17.1.2
Das Beispiel zeigt die Ausgabe, wenn ich versuche über eine PPPoE-Verbindung ein anderes Netz zu erreichen. Mein PING-Datagramm ist 1500 Byte groß, es gehen aber nur 1492 Byte über den nächsten Hop. Wenn ich es 8 Byte kleiner mache, funktioniert es:
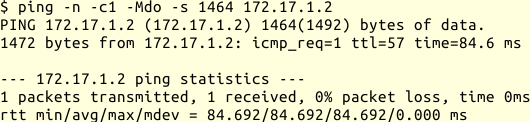
ping -n -c1 -Mdo -s 1464 172.17.1.2
Bei gestörter Path-MTU-Discovery werde ich die Fehlermeldung beim ersten Test nicht sehen, sondern einfach keine Antwort bekommen. Dann muss ich dem Datenpfad folgen und sehen, wie weit meine Datagramme kommen.
Habe ich ein Problem mit der Path-MTU-Discovery festgestellt, ist die nächste Frage, wie ich das abstelle.
Die schnellste Lösung ist, die MTU des Senders zu reduzieren. Damit verringere ich die nutzbare Bandbreite, weil auf Grund der kleineren Datenpakete das Verhältnis von Nutzdaten zu Protokolldaten ungünstiger wird. Darum ziehe ich das im Allgemeinen nur als temporäre Lösung in Betracht.
Für TCP habe ich auf den Gateways oft die Möglichkeit, die MSS-Option beim Verbindungsaufbau zu modifizieren, so dass alle TCP-Verbindungen über den entsprechenden Weg automatisch mit einer geringeren maximalen Größe der Datagramme arbeiten. Das Stichwort, wonach ich in der Dokumentation suche, lautet MSS-Clamping. Das ist insbesondere dadurch vorteilhaft, weil es nur die TCP-Verbindungen betrifft, die über den problematischen Abschnitt laufen. Außerdem muss ich nichts an den Endpunkten der Verbindung einstellen.