12. Netzwerkperformance
Manchmal scheint alles in Ordnung zu sein und trotzdem sind die Kunden nicht zufrieden. Performance ist ein heikles Thema, weil jeder seine eigene Vorstellung davon hat, was ausreichende Performance ist. So heikel, dass mancher sein Heil in immer “dickeren” Leitungen mit immer höherer Datenübertragungsrate sucht, um sich nicht näher mit dem eigentlichen Problem beschäftigen zu müssen.
Was die Sache so schwierig macht, ist, dass ein Performance Problem sehr viele Aspekte haben kann.
Da gibt es mitunter eine Diskrepanz zwischen wahrgenommener Performance und realer Performance. Ein Kunde ruft an, weil “sein E-Mail-Programm nicht funktioniert”. Er schreibt die E-Mail, drückt auf Senden und dann friert das Programm ein. Bei genauer Betrachtung stellt sich heraus, dass da ein Anhang von mehreren MB an der E-Mail hängt und die Leitung beim Upload nur eine maximale Datenübertragungsrate von ein paar hundert kBit/s hat. Ein kurzes Nachrechnen von verfügbarer Datenübertragungsrate und zu sendenden Daten ergibt bereits eine Dauer von mehreren Minuten bei alleiniger Nutzung der Leitung durch diesen Upload.
Aber auch reale Performance-Probleme können vielfältige Ursachen haben, die es einzugrenzen gilt. Oft genug sind diese Probleme intermittierend, dass heißt, in einem Moment da und im nächsten weg. Darum ist die Fehlersuche bei Problemen mit der Performance fast immer mit dem Sammeln von Daten verbunden.
Wenn ich ein Performance-Problem untersuche, beginne ich zunächst die Charakteristiken des Problems so genau wie möglich zu bestimmen.
Dann versuche ich das Problem grob zu klassifizieren:
- Ist es ein normales Problem, weil zu viele Daten gesendet werden sollen?
- Ist es vielleicht ein DNS-Problem mit Verzögerung am Anfang?
- Gibt es Probleme mit dem Durchsatz bei längeren Downloads?
- Liegt das Problem eher an der Latenz bei interaktiven Programmen?
Auch die Art des verwendeten Protokolls kann Hinweise auf mögliche Probleme geben. So gehen bei datagrammorientierten Protokollen wie UDP Daten einfach verloren, während bei datenflussorientierten Protokollen wie TCP Zeit verloren geht, während das Protokoll die Daten nochmals sendet.
Bei der Klassifizierung hilft es mir, wenn ich bereits bei der Aufnahme des Problems nach Anzeichen für mögliche Ursachen Ausschau halte, um in der betreffenden Richtung detaillierter nachzufragen.
Ursachen für Performanceprobleme
Suche ich nach der aktuellen Ursache für Performanceprobleme, muss ich wissen, welche Ursachen prinzipiell in Frage kommen und welche Charakteristika diese haben, damit ich gezielt nach relevanten Hinweisen suchen kann.
Daher gebe ich zunächst einen Überblick über mögliche Ursachen für Performanceprobleme im Netz.
Paketverluste
Eine offensichtliche Ursache für Performanceprobleme sind massive Paketverluste. Die Betonung liegt hierbei auf massive, da zum Beispiel das TCP-Protokoll Paketverluste gezielt zur dynamischen Anpassung der Übertragungsgeschwindigkeit verwendet, Details dazu finden sich in Kapitel 9. Diese erwünschten Paketverluste treten vor allem bei lange laufenden Verbindungen auf, die sehr viele Daten übertragen, wie der Download einer größeren Datei.
In den meisten anderen Fällen deuten Paketverluste auf ein Problem oder eine Beschränkung hin. Dann versuche ich die Ursache für den Paketverlust zu finden. Oft lässt sich dieser auf eine der folgenden Ursachen zurückführen:
- Eine überlastete Leitung: es sollen mehr Daten pro Zeiteinheit gesendet werden, als bestimmungsgemäß über den betroffenen Leitungsabschnitt möglich ist.
- Eine schlechte Leitung: es ist nicht möglich, die volle Datenübertragungsrate zu nutzen, die über den Leitungsabschnitt zur Verfügung stehen sollte.
- Ein überlastetes Gateway: dieses benötigt zu viel Zeit, um Daten zwischen den Interfaces zu bewegen.
- Eine schlechtes Gateway: Datenpakete werden beschädigt und von nachfolgenden Komponenten verworfen. Gateway in diesem Sinne kann auch ein Switch sein.
DNS-Probleme
Ein anderes Problem, dass mitunter als Performanceproblem im Netz angesehen wird, ist ein Teilausfall im DNS. Meist wird das Problem beim Browsen im Internet wahrgenommen. Die erste Beschreibung lautet oft pauschal: “das Internet ist heute wieder schnarchlangsam”. Auf Nachfragen heißt es: wenn eine Seite angewählt wird, passiert erstmal nichts. Irgendwann geht es los und dann kommt die Seite eigentlich recht schnell. In diesem Fall überprüfe ich zunächst die DNS-Einstellungen und beobachte den DNS-Verkehr.
Latenz
Eine weitere mögliche Ursache für Performanceprobleme liegt in der Latenz der
Datenpakete, also der Zeit die benötigt wird, um ein Datenpaket vom Sender zum
Empfänger zu bewegen.
Diese Zeit kann ich mit dem Programm ping abschätzen.
Die Latenz ist ungefähr die Hälfte der Round-Trip-Time (RTT).
Üblicherweise wirkt sich eine hohe Latenz vor allem auf interaktive Verbindungen und kurze Übertragungen spürbar aus. Ab einer bestimmten Dauer behindern die Verzögerungen zwischen gesendeten und empfangenen Daten spürbar den Arbeitsfluss. Langlaufende TCP-Downloads sind eher selten von großer Latenz betroffen, wenn Sender und Empfänger genügend große Puffer haben. Zumindest wenn es sich um die natürliche Latenz auf Grund der Leitungseigenschaften handelt, die sich nicht im Laufe der Übertragung zum Beispiel durch Überlast erhöht.
Bufferbloat
Ein Problem, dass in der Fachliteratur als Bufferbloat bezeichnet wird, ist die künstliche Erhöhung der Latenz durch Puffer in den Gateways. Diese kommt zustande, wenn bei einem Gateway mehr Daten ankommen, als gesendet werden können. Im Laufe der Zeit wurden Gateways mit immer mehr Puffer ausgestattet, damit bei kurzfristiger Überlast, sogenannten Bursts, keine Datenpakete verloren gehen und die Leitungen besser ausgelastet werden können. Das Gateway speichert die Datenpakete kurz zwischen und sendet sie, sobald die Sendeleitung frei ist. Die Latenz erhöht sich zwar, aber das Datenpaket kommt an.
Problematisch sind diese Puffer genau dann, wenn es zu chronischer Überlast kommt und die Puffer längerer Zeit gefüllt sind. Dann gehen neu ankommende Pakete trotzdem verloren und zusätzlich haben wir eine hohe Latenz, weil das Gateway zuerst die gepufferten Daten sendet und dann die neu angekommenen. Dadurch werden die Paketverluste viel später wahrgenommen, als sie auftreten.
Wenn ungeregelte Datenströme die Überlast hervorrufen, hilft nur die Datenübertragungsrate zu erhöhen, oder den Datenstrom umzuleiten, beziehungsweise gezielt zu reduzieren.
Geregelte Datenströme, wie TCP, passen normalerweise ihre Sendegeschwindigkeit so an, dass die zur Verfügung stehende Datenübertragungsrate möglichst optimal genutzt wird. Leider funktioniert diese Regelung bei Bufferbloat nicht auf Grund der durch den Puffer eingeführten zusätzlichen Latenz. Da TCP die Sendegeschwindigkeit bei Paketverlusten herunter regelt, diese aber erst auftreten, wenn der Puffer voll ist, ist es dann bereits zu spät.
Natürlich tritt das Problem mit Bufferbloat nur an den Stellen auf, wo Daten an einem Gateway nicht so schnell abfließen können, wie sie ankommen. Das heisst an Gateways mit unterschiedlichen Schnittstellengeschwindigkeiten oder, wenn das Gateway an einer Schnittstelle Daten sendet, die über mehrere Schnittstellen ankommen.
Kenne ich das Netz, dann weiss ich, wo die neuralgischen Punkte sind und schaue mir dort die Schnittstellenauslastung an. Dabei hilft mir ein Monitoring der Datenübertragungsraten an den Schnittstellen. Ein konkreter Hinweis auf Bufferbloat ist eine stark erhöhte Latenz zusammen mit einer unter Vollast betriebenen Leitung.
Unnötiger Datenverkehr
Schließlich liegt eine mögliche Ursache für Performanceprobleme im Netz in unnötigem Datenverkehr, der die Leitungen zusätzlich zum regulären Datenverkehr belastet.
Hierbei ist es nicht einfach, zu entscheiden, welcher Datenverkehr unnötig ist und welcher nicht. Zudem ist es auch nicht trivial, die Auslastung anteilig einzelnen Datenströmen zuzuordnen. Mit Netflow lässt sich dass zumindest ansatzweise einschätzen.
In diesem Fall überlege ich, ob durch geschicktere Platzierung von Servern und Arbeitsstationen der Bedarf an Datenübertragungsrate reduziert werden kann. Das ist aber ein Thema für die Netzwerksplanung und nicht für die Fehlerbeseitigung.
Kurzfristig hilft vielleicht eine Priorisierung des Datenverkehrs.
Überlast des Rechners
Manchmal erweist sich das Netzperformanceproblem auch einfach als Performanceproblem des Servers oder Client-Rechners. Wenn sich aus allen beobachteten Netzwerkparametern kein anderer Hinweis ergibt, verliere ich auch diese mögliche Ursache nicht aus den Augen.
Performancemessungen im Netz
Nachdem ich im vorigen Abschnitt auf mögliche Ursachen für Performanceprobleme im Netz eingegangen bin, will ich nun etwas detaillierter darauf eingehen, wie ich Netzparameter bestimmen kann.
Diese Parameter erfasse ich, wenn möglich, vor dem produktiven Einsatz von Netzwerkverbindungen, als Baseline für spätere Vergleichsmessungen, wenn ich Fehler vermute.
Maximale Datenübertragungsrate
Ich verweise hier wieder auf [Sloan2001].
Dort ist beschrieben, wie ich nur mit ping als Werkzeug die
maximale Datenübertragungsrate jedes
einzelnen Netzsegmentes zwischen Sender und Empfänger bestimmen kann.
Da ich bei Netzen außerhalb meines Einflussbereiches nicht immer damit rechnen
kann, auf PING eine Antwort zu bekommen, muss ich gegebenenfalls zu anderen
Mitteln greifen.
Wenn ich jedoch das Prinzip verstanden habe, kann ich auch andere Werkzeuge,
wie zum Beispiel traceroute, einsetzen und die Laufzeit mit tcpdump oder
wireshark bestimmen.
Das Verfahren funktioniert folgendermaßen:
- Ich bestimme die Adressen der Router auf dem Pfad, den ich untersuchen
will, mit
traceroute. - Ich sende direkt an die Router PING-Pakete mit 100 Byte und 1100 Byte Paketgröße und notiere mir die RTT der Antworten.
- Für jedes Segment betrachte ich die RTT des Routers davor (1) und
dahinter (2).
Für jede Paketgröße bestimme ich die Differenz der Antwortzeiten für den vorderen und hinteren Router. Damit eliminiere ich den Einfluss des Pfades bis zum vorderen Router.
Es bleiben zwei Zeiten, für das große und das kleine Datenpaket. Die Differenz zwischen diesen beiden Zeiten ist die benötigte Zeit, um 1000 Byte über dieses Segment zu transportieren.
Diese Zeit teile ich durch 2, weil mich nur die einfache Zeit für die Übertragung interessiert. Die Anzahl der Bytes (1000) multipliziere ich mit 8, da die Datenübertragungsrate üblicherweise in bps (bits per second) angegeben wird.
Damit komme ich zu folgender Gleichung:
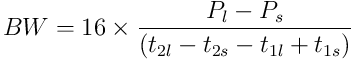
Dabei sind
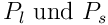 die Größe der großen (l) und
kleinen (s) Datenpakete in Byte.
die Größe der großen (l) und
kleinen (s) Datenpakete in Byte.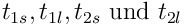 sind die RTT in
Millisekunden.
sind die RTT in
Millisekunden.Das Ergebnis BW ist in kbps.
Falls ich mehrere Datenpakete mit der gleichen Größe gesendet habe, verwende ich für die Berechnung nicht den Durchschnitt sondern die kleinste RTT, weil diese der wahren, nicht mit anderen Übertragungen geteilten Datenübertragungsrate am nächsten kommt. Es versteht sich auch von selbst, dass ich mir für die Messung einen Zeitpunkt heraussuche, zu dem möglichst wenig anderer Datenverkehr die Messung beeinflusst.
Bin ich gezwungen, auf andere Datenpakete auszuweichen, kann ich auch tcpdump
zur Messung der RTT verwenden.
Dabei muss ich beachten, dass ich bei konstanter Größe der Antwortpakete, zum
Beispiel bei ICMP-Unreachable Nachrichten, die gemessene Zeitdifferenz nicht
halbieren darf.
Da traceroute ebenfalls die RTT der einzelnen Hops ausgibt und einige
Varianten von Traceroute verschieden große Datagramme senden können, kann ich
mitunter auch dieses direkt für die Messungen einsetzen.
In diesem Fall ist der konstante Faktor in der Gleichung statt 16 nur 8, da
die ICMP-Unreachable-Nachrichten eine konstante Größe haben.
Latenz
Die Latenz kann ich sehr gut mit ping abschätzen, sie entspricht der Hälfte
der angegebenen RTT.
Um den Einfluss möglicher Puffer aufzudecken, kann ich zusätzlich auf Teilstrecken des Pfades eine Last legen und dabei die Veränderungen der RTT beobachten.
Lasttest mit Ping
Mit dem Befehl
# ping -f rechnername
sendet Ping Datenpakete, so schnell es geht, zum Zielrechner.
Dazu benötige ich Superuserrechte.
Diesen Aufruf kann ich mit der Option -l $preload kombinieren, so dass Ping
so viele Datenpakete sendet, ohne auf Antwort zu warten.
Damit kann ich auf einem Segment Netzwerklast erzeugen.
Zusätzlich zur normalen Statistik (min/avg/max/mdev) zeigt Ping dann am Ende
zwei Werte: IPG und EWMA.
IPG (Inter Packet Gap) ist die Zeit zwischen dem Senden zweier Datenpakete. Für Ethernet ist die Minimalzeit auf die Zeit festgelegt, in der 96 Bit übertragen werden. Das sind 9,6 µs für 10 MBit/s Ethernet und 9,6 ns für 10 GBit/s. Diese Zeit wird automatisch vom Ethernetadapter an jedes Datenpaket angehängt. Das angezeigte IPG kann ich als Maß verwenden, um abzuschätzen, wie effizient die Kombination Betriebssystem, Netzwerkkarte, Netzwerk Daten senden kann.
EWMA steht für Exponential Weighted Moving Average. Bei diesem Durchschnitt werden die letzten RTT höher gewichtet als ältere. Im Normalfall sollte dieser gleich dem Mittelwert für RTT sein. Weicht er signifikant ab, deutet das auf einen Trend hin. Dafür benötige ich aber einen länger laufenden Ping und da EWMA am Ende ausgegeben wird, wird der Trend erst am Ende dieser Messung offenbar.
Durchsatz
Um den Durchsatz zu messen, greife ich auf entsprechende Programme wie iperf
zurück.
Diese erlauben mir den Durchsatz eines Pfades mit TCP oder UDP zu bestimmen,
wobei ich die Charakteristika der beiden Protokolle ausnutzen kann.
Dabei kann ich den Durchsatz entweder in jeweils einer Richtung oder gleichzeitig in beiden Richtungen messen. Ich muss jedoch immer im Hinterkopf behalten, dass manche Ethernetkarten beziehungsweise die Treiber dafür nicht die volle mögliche Datenübertragungsrate liefern können.
Habe ich signifikante Unterschiede im Durchsatz bei den verschiedenen
Richtungen, kann das ein Hinweis auf fehlangepasste Schnittstellen
(Half-Duplex, Full-Duplex) sein.
Diesem kann ich mit mii-tool oder ethtool nachgehen.
Analyse des Datenverkehrs
Nicht zu unterschätzen für die Problemanalyse sind die Daten, die ich vom Monitoring erhalten kann. Natürlich muss ich es vorher aufgesetzt haben und sollte möglichst schon Vergleichsdaten aus der Vergangenheit zur Verfügung haben.
Habe ich keine Monitoringdaten oder helfen diese mir nicht weiter bei der
Analyse, dann habe ich als letzte Möglichkeit immer noch, den Datenverkehr an
verschiedenen Stellen im Netzwerk mit tcpdump, wireshark oder ähnlichen
Werkzeugen mitzuschneiden und anschließend die Mitschnitte zu analysieren.
MRTG, Cacti und ähnliche
Damit bekomme ich Informationen, wieviele Daten an den einzelnen Schnittstellen pro Zeiteinheit übertragen wurden, umgerechnet in eine durchschnittliche Auslastung. Ich sehe zwar nicht jeden einzelnen Burst, aber eine hohe Ausnutzung der Schnittstelle über fünf Minuten oder länger kann schon signifikant sein für die Fehlersuche.
Da die Messwerte meist aller fünf Minuten via SNMP abgefragt werden, belasten diese das Netzwerk nicht übermäßig.
Netflow
Noch aussagekräftiger sind die Daten von Netflow. Damit kann ich nicht nur Lastspitzen erkennen, sondern auch, welcher Verkehr die meiste Datenübertragungsrate benötigte oder die meisten Datenpakete.
Für Netflow benötige ich Sensoren auf den Routern und eine geeignete
Monitoring-Software, wie zum Beispiel NfSen.
Als Sensor für Linux eignet sich zum Beispiel fprobe.
Natürlich belasten die Sensoren die Router und die verschickten Zusammenfassungen erzeugen zusätzlichen Datenverkehr. Darum setze ich Netflow nur auf strategisch wichtigen Routern ein.
Analyse von Paketmitschnitten
Wenn ich zu einem Performanceproblem keine Erklärung finde, greife ich zum letzten Mittel und schneide die einzelnen Datagramme der betreffenden Verbindung mit, wenn möglich an verschiedenen Stellen im Netzwerk. Die anschließende Analyse der Mitschnitte ist aufwendig und benötigt einiges an Zeit.
TCP-Übertragungen analysieren
TCP-Übertragungen werden gesteuert durch die Parameter, die der Empfänger in den Bestätigungsdatagrammen (Ack-Paketen) setzt, durch das Timing der Ack-Pakete und durch Paketverluste. Letztendlich ist es der TCP-Stack des Senders, der entscheidet, wann er ein Datenpaket sendet und welches, das heißt, ob er das nächste ungesendete schickt oder ein bereits gesendetes wiederholt.
Generell interessieren mich bei der Auswertung von TCP-Verbindungsmitschnitten
- die Sequenz-Nummer,
- die Acknowledge-Nummer,
- das Receive-Window,
- die Anzahl der gesendeten Oktetts (die Länge des Pakets),
- die Richtung und
- der Zeitstempel des Datagramms.
Diese sechs Angaben lassen sich gut in einem Sequenz-Zeit-Diagramm
visualisieren, was die Auswertung beschleunigt.
Tim Shepard ist in seiner Masterarbeit, [Shepard1991],
ausführlich darauf eingegangen.
Das Programm xplot eignet sich gut für die Auswertung, mit tcptrace
kann ich den Paketmitschnitt dafür aufbereiten.
Will ich eine TCP-Verbindung anhand eines Mitschnitts analysieren, muss ich zwischen verschiedenen Szenarien unterscheiden und deren Rahmenbedingungen berücksichtigen.
- Sender und Empfänger sind im gleichen LAN-Segment, die Übertragungszeiten
liegen unter 1 ms. In diesem Fall ist es fast egal, ob der Mitschnitt beim
Sender, Empfänger oder einem dritten Rechner im gleichen Segment
aufgezeichnet wird.
Hier brauche ich mir keine Gedanken über variable Laufzeiten machen.
- Sender und Empfänger befinden sich in verschiedenen Netzsegmenten, die
Übertragungszeiten liegen deutlich über 1 ms, oft über 10 ms und manchmal
über 100 ms.
Ich muss mit Paketverlusten und variablen Paketlaufzeiten rechnen, die
durch das Netz verursacht werden.
Bei der Analyse eines Mitschnitts muss ich die Position des Proberechners berücksichtigen, der den Mitschnitt aufzeichnet.
Ist der Proberechner im selben LAN-Segment wie der Sender, “sehe” ich die Daten genau wie der sendende TCP-Stack, kann dessen Entscheidungen nachvollziehen und an Hand der Ack-Pakete und ihrer Zeitstempel auf den Zustand des Netzes und des Empfängers schließen.
Ist der Proberechner im selben LAN-Segment wie der Empfänger, “sehe” ich die Verbindung genau wie der Empfänger und kann dessen Entscheidungen nachvollziehen. Hier schließe ich aus der Reihenfolge und dem Timing der Datenpakete auf den Zustand des Netzes und des Senders.
Ist der Proberechner zwischen dem LAN-Segment des Senders und dem des Empfängers positioniert, so muss ich bei der Interpretation der Daten- und Ack-Pakete berücksichtigen, dass bei beiden variable Laufzeiten und Paketverluste auftreten können.
Habe ich nur einen Mitschnitt zur Verfügung, konzentriere ich mich auf das oben gesagte. Stehen mir Mitschnitte derselben Verbindung von verschiedenen Stellen des Netzes zur Verfügung, dann kann ich durch Vergleich der einzelnen Mitschnitte bessere Aussagen zum Zustand des Netzes machen.
 |
Mache dich mit der Analyse von Verbindungsmitschnitten vertrautNimm zwei Rechner in verschiedenen Netzsegmenten.
|
Maßnahmen
Je nachdem, was ich als Ursache für das Performanceproblem ermittelt habe, greife ich zur entsprechenden Abhilfe.
Bei überlasteter Hardware, wie Gateways, Switches und ähnlichem, schaue ich mich um, ob ich etwas leistungsfähigeres finde und einsetzen kann.
Liegt der Flaschenhals in einer Leitung zu einem anderen Standort, muss ich vielleicht eine bessere Leitung anmieten, kaufen oder verlegen lassen.
Kurzfristig kann ich das Problem vielleicht mit QoS verlagern. Will ich QoS langfristig im Netz einsetzen, muss ich dafür sorgen, dass das immer gut dokumentiert wird und dass die Administratoren ausreichend geschult werden. Dabei ist QoS nicht nur auf Traffic-Shaping beschränkt. Einige Dienste, wie zum Beispiel Squid-Proxy-Server enthalten Möglichkeiten zur gezielten Beschränkung der Datenübertragungsraten.
Dabei muss ich auf Nebeneffekte achten. In einem Fall blieb für den E-Mail-Verkehr so wenig Datenübertragungsrate, dass einzelne, sehr große E-Mail mehrere Stunden für die Übertragung benötigten. Dementsprechend musste ich die Timer an den Mailservern anpassen.
Eine gute Idee ist in vielen Fällen, den Traffic zu reduzieren. Kurzfristig könnte ich einige Dienste abschalten oder deren Traffic niedriger priorisieren. Langfristig kann ich durch geschickte Platzierung von Servern und den Einsatz von Proxy-Servern den Traffic reduzieren.
Sollte das Netzwerkperformanceproblem sich als Performanceproblem des Servers oder Client-Rechners erweisen, kann ich es wie in Kapitel 7 beschrieben, angehen.
Traffic-Shaping
Manchmal bleibt mir nur, den Datenverkehr einzuschränken und zu priorisieren. Dabei muss ich einige Dinge beachten:
- Will ich den Datenverkehr kontrollieren, muss ich sicherstellen, dass ich diesen am Flaschenhals steuere. Das ist meist der Übergang von einer schnellen auf eine langsame Leitung oder ein Gateway, an dem mehrere ankommende Leitungen auf eine abgehende Leitung treffen.
- Ich kann nur den abgehenden Verkehr direkt beeinflussen. Das heißt, wenn ich mich um ein langsames Datensegment kümmere, begrenze ich von beiden Seiten den in das Segment gehenden Verkehr.
- Wenn ich gezielt nur einen Teil des Datenverkehrs begrenzen will, mache ich das so nah wie möglich an der Quelle.
Das Linux Advanced Routing & Traffic Control HowTo (LARTC) liefert, insbesondere in Kapitel 9, Queueing Disciplines for Bandwidth Management, das nötige Hintergrundwissen.
Hier zeige ich an einem Beispiel, wie die verschiedenen Elemente zusammenspielen. Dabei will ich an einer 100 MBit/s Leitung den Datenverkehr zu bestimmten Geräten auf 10 MBit/s beschränken, um diese Geräte zu entlasten. Ich verwende die Queueing Discipline (Qdisc) Hierarchical Token Bucket (HTB), weil diese einfach zu konfigurieren ist und zuverlässig funktioniert.
Zunächst ändere ich die Qdisc des Interface auf HTB:
DEV=eth1
tc qdisc add dev $DEV root handle 1:0 htb default 11 r2q 65
Mit default 11 habe ich festgelegt, dass jeglicher nicht anders
klassifizierter Datenverkehr bei Klasse 11 einsortiert wird.
Die Angabe r2q 65 dient der Berechnung des Quantums, mit welchem
bestimmt wird, wie der Datenverkehr aufzuteilen ist,
der zwischen dem konfigurierten Minimum und der Obergrenze liegt.
Weitergehende Erläuterungen dazu finden sich in den
FAQ des LARTC.
Das Quantum wird berechnet als rate geteilt durch r2q.
Es sollte größer als die MTU sein, damit mindestens ein vollständiges
Datenpaket gesendet werden kann.
Die obere Grenze liegt bei 60000.
Zu dieser HTB Qdisc füge ich eine Klasse für den gesamten Traffic am Interface:
tc class add dev $DEV parent 1:0 classid 1:1 htb \
rate 99mbit ceil 99mbit burst 1200kb cburst 1200kb
An dieser Stelle habe ich die Möglichkeit, die Datenrate des gesamten Verkehrs
zu beschränken, wenn ich zum Beispiel ein langsames Modem über Ethernet
angeschlossen habe.
Dann wähle ich einen Wert für rate und ceil, der etwas niedriger
als die Übertragungsgeschwindigkeit ist und stelle somit sicher, dass sich die
Datenpakete in diesem Rechner stauen und nicht am Modem.
Mit burst und cburst stelle ich ein, wieviel Traffic maximal mit voller
Geschwindigkeit gesendet werden kann, wenn längere Zeit kein oder wenig
Traffic ankam.
Nun benötige ich noch eine Klasse für den “eingeschränkten” und eine für den “normalen” Datenverkehr:
tc class add dev $DEV parent 1:1 classid 1:10 htb \
rate 5mbit ceil 10mbit
tc class add dev $DEV parent 1:1 classid 1:11 htb \
rate 20mbit ceil 99mbit burst 1200kb cburst 1200kb
Die Klasse für den “normalen” Datenverkehr ist wichtig, da sonst sämtlicher Datenverkehr in der beschränkten Klasse landet und ebenfalls begrenzt wird.
Nun muss ich den Datenverkehr noch richtig einsortieren, damit die Beschränkung wirksam wird. Dazu füge ich einen Filter ein:
tc filter add dev $DEV parent 1:0 prio 0 protocol ip \
handle 10 fw flowid 1:10
Dieser Filter verwendet Markierungen an den Datagrammen, die
iptables anbringt.
iptables -A FORWARD -d 192.168.7.16/32 -p tcp \
-j MARK --set-xmark 0xa/0xffffffff
iptables -A FORWARD -d 192.168.7.22/32 -p tcp \
-j MARK --set-xmark 0xa/0xffffffff
Damit ist die Auswahl, des beschränkten Datenverkehres entkoppelt von der
eigentlichen Beschränkung und ich kann alle Möglichkeiten von
iptables und ip6tables zur Selektion nutzen.
Bufferbloat
Bei Bufferbloat an einem Übergang zu einer Leitung mit niedriger Datenübertragungsrate habe ich nicht viele Möglichkeiten.
Eine wirksame Abhilfe bei Bufferbloat verspricht das Queue-Management mit dem CoDel-Verfahren. Dabei bekommen ankommende Datenpakete einen Zeitstempel. Sobald ein Paket zu lange in einer Queue verbleibt, werden nachfolgende Pakete verworfen, noch bevor die Queue überfüllt ist. Die TCP-Flusskontrolle der betroffenen Verbindungen kann schneller reagieren und drosselt die Transfer-Rate eher, wodurch die Leitung entlastet wird.
Diese Lösung funktioniert recht gut und hat den Vorteil, dass außer dem Queue-Management am Router nichts geändert werden muss. Ein weiterer wesentlicher Vorteil ist, dass der Administrator keine Parameter bestimmen oder einstellen muss, wodurch eine mögliche Fehlerquelle entfällt.
In [ctTZ2013a] erläutern die Autoren Queue-Management mit CoDel für den Laien verständlich und in [ctTZ2013b] zeigen sie, wie man mit der Firewall-Appliance IPFire erste eigene Erfahrungen damit sammeln kann.
CoDel ist im Linux-Kernel ab Version 3.5 enthalten. Bei einem älteren Kernel, der CoDel nicht unterstützt, bleibt mir nur, mit QoS und Priorisierung genügend Datenübertragungsrate für wichtige Anwendungen zu reservieren. Dazu muss ich die Datenströme genau analysieren.