5. Totalausfall
Ein Totalausfall bedeutet für mich zuallererst: der Rechner selbst ist keine Hilfe bei der Fehlersuche. Das muss nicht heißen, dass der Rechner überhaupt nicht mehr reagiert, aber auf jeden Fall stehen mir nicht alle Werkzeuge zur Verfügung, die ich sonst zur Analyse einsetzen könnte.
Ich betrachte die folgenden Probleme als Totalausfall eines Rechners.
- Hardwarefehler, der Rechner reagiert überhaupt nicht beim Einschalten. Abgesehen von dem Tipp, den Stromanschluss zu überprüfen, gehe ich darauf hier nicht weiter ein.
- Boot-Probleme, zwar passiert etwas, die Hardware scheint größtenteils in Ordnung, aber das Betriebssystem wird nicht gestartet. Ich analysiere den Bootprozess Schritt für Schritt, beobachte, wie weit das System kommt und versuche die Ursache zu ermitteln.
- Einfrieren, der Rechner war normal gestartet, hat eine Zeit lang gearbeitet, aber jetzt reagiert er nicht mehr. Ich versuche zunächst den Rechner mit Magic SysRequest geordnet neu zu starten und nachträglich zu analysieren. Falls möglich, werte ich die mit SysRequest gewonnenen Erkenntnisse aus.
- Überlast, Swapping, Thrashing. Ich sehe oder höre, dass der Rechner intensiv arbeitet. Trotzdem reagiert er sehr langsam. Auf Grund von Timeouts kann ich mich nicht einmal mehr anmelden, in einer Shell bekomme ich kein Programm gestartet. Wenn ich die Last nicht auf anderem Weg vom Rechner nehmen kann, bleibt mir nur, den Rechner neu zu starten. Anschließend versuche ich zu ermitteln, was die Überlast ausgelöst hatte.
- Ausfälle bei virtuellen Maschinen.
Das sind die gleichen Fehler wie bei “echten” Maschinen aus Blech.
Hinzu kommen Probleme mit der Virtualisierungsschicht.
Im Gegenzug bekomme ich mehr Diagnosemöglichkeiten an die Hand.
Neben dem Totalausfall des Gastsystems gibt es noch die Möglichkeit, das das Wirtssystem ausgefallen ist. Diesen Fehler behandle ich, wie oben beschrieben.
Bei den Gastsystemen sind meine Optionen abhängig von der verwendeten Virtualisierungslösung und deren Werkzeugen zur Diagnose. Manchmal kann ich einfach die Festplattenpartitionen des Gastsystems im Hostsystem oder einem anderen Gastsystem einhängen und dort untersuchen. Damit stehen mir zusätzliche Werkzeuge zur Verfügung.
Bootprobleme
Zwar treten Bootprobleme selten auf, wenn sie aber erstmal da sind, bekommen sie die volle Konzentration, weil eben wirklich “nichts mehr geht”.
Um die Bootprobleme eines Systems analysieren und beheben zu können, muss ich das Verhalten eines gesunden Systems beim Startvorgang kennen. Dieses zeichnet sich durch verschiedene Phasen mit unterschiedlicher Zuständigkeit und dementsprechend unterschiedlicher Herangehensweise aus. Grob teile ich den Startvorgang eines Linux-Rechners in die folgenden Phasen ein:
- Die Firmware des Rechners initialisiert die Hardware. Das ist bei einem PC gekennzeichnet durch die verschiedenen BIOS-Meldungen. Eingriffe an dieser Stelle sind abhängig von der konkreten Hardware und nicht explizit Thema dieses Buches, obwohl diese das Verhalten des Linux-Systems sehr wohl beeinflussen.
- Die Firmware lädt und startet den Bootmanager. Je nach Bootmanager habe ich hier bereits die Möglichkeit, das spätere Verhalten des Linux-Systems zu steuern.
- Der Bootloader als Bestandteil des Bootmanagers lädt den Kernel und das Initramfs und startet den Kernel. Hier werden Änderungen, die ich im Bootmanager vorgenommen habe, zum ersten Mal wirksam.
- Der Kernel nimmt die wichtigsten Systemkomponenten in Betrieb und startet ein Initialisierungsskript vom Initramfs. In dieser Phase kann ich nicht eingreifen, nur beobachten.
- Das Initialisierungsskript des Initramfs lädt Treiber, überprüft das Root-Dateisystem und hängt dieses ein. Bei einem Problem startet es manchmal eine Shell, in der ich dieses interaktiv bearbeiten kann.
- Sobald das Root-Dateisystem als rootfs eingehängt ist, übergibt das Initialisierungsskript an den Initd des Systems, der über Skripts weitere Dateisysteme einhängt sowie Hintergrunddienste und Anmeldeprogramme startet. Wenn dieser auf Probleme mit Dateisystemen trifft, bietet er an, das Problem in einer Shell - nach Eingabe eines Kennworts - zu lösen, oder einen Neustart zu versuchen.
- Sobald ich mich am System regulär anmelden kann, ist der Rechner benutzbar, auch wenn noch Systemteile initialisiert werden.
Startphasen des Rechners identifizieren
Da ich, je nachdem in welcher Phase ein Problem auftritt, auf verschiedene Weise an die Lösung herangehe, ist es wichtig, dass ich die einzelnen Phasen erkennen und auseinander halten kann.
Dazu muss ich gegebenenfalls die nötigen Startinformationen erst freilegen. Das können zum einen Einstellungen im BIOS sein, die abhängig von der Hard- und Firmware und daher nicht Thema dieses Buches sind.
Viele moderne Linux-Distributionen verstecken die Informationen, die Linux-Kernel und System auf den Bildschirm schicken. Mit dem Bootmanager kann ich die betreffenden Kerneloptionen ändern, um mehr Informationen zu erhalten. So entferne ich zum Beispiel die folgenden Kerneloptionen:
quietrhgbbei Fedora oder Red Hatsplashbei Ubuntusplash=silentbei OpenSusevt.handoff=7bei Ubuntu 11.10
Gibt es bei Grub2 in der Konfiguration die Zeile
set gfxpayload=$linux_gfx_mode
ändere ich diese in
set gfxpayload=text
Habe ich die Bootinformationen sichtbar gemacht, kann ich mit Ihrer Hilfe den Bootvorgang besser diagnostizieren und die einzelnen Phasen unterscheiden.
Nach den Firmwaremeldungen meldet sich der Bootmanager.
Manchmal nur mit einer kurzen Zeile, die den Namen des Bootmanagers enthält.
Oft aber auch mit einem Menü, aus dem ich das System, welches starten soll,
auswählen kann.
Fehlt das Menü, kann ich es mit <ESC> oder <TAB> hervorrufen,
bevor der Bootloader den Kernel lädt.
Die Meldung ‘Loading Kernel’ oder ‘Loading initial ramdisk’ zeigt den Übergang
von Phase 2 zu Phase 3 an.
Dieser folgen Dutzende Kernelmeldungen zur Hardware-Initialisierung,
die bei der Kernel-Option quiet unterdrückt worden wären.
Eine Meldung wie ‘dracut: dracut …’ bei Fedora oder ‘Write protecting the kernel …’ und Meldungen von Udev zeigen an, dass der Kernel geladen ist und die Skripte des Initramfs die Arbeit übernommen haben.
Meldungen wie ‘Switching root’ und ‘Welcome to xyz Linux’ zeigen an, dass die Skripte des Initramfs fertig sind und der Init-Daemon des Systems übernimmt. Sobald ein Konsolenlogin oder grafisches Login präsentiert wird und ich mich anmelden kann, betrachte ich den Systemstart als abgeschlossen, auch wenn im Hintergrund noch der eine oder andere Dienst gestartet wird.
Mit dem Wissen um die Übergänge zwischen den einzelnen Phasen des Startvorgangs kann ich mich nun den Problemen in den einzelnen Bootphasen zuwenden.
Da Probleme mit der Firmware abhängig von der konkreten Hardware sind, behandle ich diese hier nicht weiter. Wichtig für die Fehlersuche ist trotzdem ein grundlegendes Verständnis der Einstellmöglichkeiten in der Firmware, weil diese Einfluss auf das Verhalten des Kernels haben können.
Probleme mit dem Bootloader
Bleibt nach den Selbsttests der Firmware der Bildschirm schwarz, kommt eine Meldung wie ‘Operating system not found’ oder erscheinen Fehlermeldungen von Grub, Lilo oder anderen Bootloadern, habe ich ein Problem mit dem Bootloader.
Eine mögliche Ursache ist, dass die Firmware den Bootmanager nicht gefunden hat. Das kann auf einen defekten Master Boot Record (MBR) hindeuten. Möglich ist auch, dass der Bootloader nicht im MBR, sondern in einer Partition installiert und diese nicht als bootfähig gekennzeichnet ist. Vielleicht wurde die Bootreihenfolge im BIOS geändert oder durch einen zusätzlich angesteckten Datenträger durcheinander gebracht. Eventuell ist die Installation des Bootmanagers beschädigt. Grub2 zum Beispiel speichert einen Teil des Bootmanagers direkt hinter dem MBR vor der ersten Partition. Vielleicht ist auch die Partition beziehungsweise das Dateisystem, welches weitere Teile des Bootmanagers enthält, beschädigt.
Wenn eine Vertauschung der Bootreihenfolge und ein zusätzlicher Datenträger ausgeschlossen werden können, starte ich den Rechner von einem Live- oder Rescue-System auf einer CD-ROM oder einem USB-Stick. Dann kann ich die Systemplatte mit allen zur Verfügung stehenden Mitteln und Werkzeugen überprüfen.
- Ist die Partitionstabelle korrekt?
- Sind die Dateisysteme in Ordnung?
- Sind alle benötigten Dateien an der richtigen Stelle?
Außerdem kann ich den Bootmanager neu installieren.
Das mache ich am besten aus dem System auf der Festplatte heraus.
Dazu hänge ich die Partitionen an den korrekten Mountpoints ein und wechsle
mit chroot in das System.
Probleme beim Start des Kernels
Nach dem der Bootloader den Kernel startet, bleibt das System stehen oder startet neu. Das passiert mitunter nach einem BIOS- oder Kernel-Upgrade oder nach Änderungen in den BIOS-Einstellungen. Daher versuche ich herauszubekommen, ob eine dieser Bedingungen hier vorliegt und ob ich diese rückgängig machen kann.
Zum Test kann ich alle Peripherie (USB, seriell, parallel, …) und alle nicht zum Booten benötigten Komponenten entfernen. Falls das System dann startet, füge ich nach und nach die einzelnen Komponenten wieder hinzu, bis der Fehler wieder auftritt.
Als nächstes kann ich systematisch die verschiedenen hardwarerelevanten Kernelparameter durchprobieren. Dann genauso die BIOS-Einstellungen und schließlich die Kombination beider.
Nachfolgend gehe ich kurz auf einige Meldungen ein, die mir bei Problemen während des Starts des Kernels begegnen können.
Kernel Panic
Nach Ausgabe einiger Zeilen bleibt der Kernel mit der Meldung ‘Kernel panic’ stehen.
Das kann an einer fehlerhaften Kernkomponente, wie Prozessor, Speicher oder Chipsatz auf dem Mainboard liegen. Insbesondere, wenn der Kernel gleich nach dem Anlaufen mit Panic abbricht. In diesem Fall muss ich mit den Kernelparametern experimentieren. Manchmal hilft eine Internet-Suche nach der gleichen Hardware in Zusammenhang mit Problemen bei Linux.
Bei Problemen mit Treibern versuche ich meist die folgenden Strategien:
- Internet-Suche mit den Informationen aus den letzten Zeilen oberhalb der Abbruchmeldung
- Suche in der Kernel-Dokumentation zu Parametern für diesen Treiber.
Bei modularen Treibern hilft auch
modinfo -p treibernamefür eine erste Übersicht. - Mit der Kerneloption
modulename.disable=1kann ich das Laden dieses Treibers unterbinden.
Wenn bereits nach einigen Zeilen der Bildschirm schwarz wird oder das System neu startet, könnte es am Grafiktreiber liegen, falls die Zeilen davor nicht auf andere Ursachen hindeuten.
Als erstes kann ich den Standard-VGA-Textmodus mit dem Kernelparameter
nomodeset einschalten.
Falls das funktioniert, könnte es an einer fehlerhaften Erkennung des Monitors
liegen.
Mit video=1024x768-24@75 gebe ich eine Auflösung von 1024x768 bei 24 Bit
Farbtiefe und einer Bildwiederholrate von 75 Hertz vor.
Funktioniert auch das, kann ich den Parameter so ändern, das er zu meinem
Monitor passt.
Sitzen die Probleme tiefer, kann ich versuchen, die Debug-Informationen des
Direct Rendering Manager (DRM) des Kernels mittels des Kernelparameters
drm.debug=14 auszuwerten.
Auch die DRM-Treiber bieten Optionen, mit denen ich experimentieren kann.
Attempted to kill init
Der Prozess mit PID 1 ist abgestürzt. Das könnte durch ein beschädigtes Initramfs verursacht sein oder, falls das System schon mit dem Root-Dateisystem arbeitet, durch beschädigte oder fehlende Dateien auf eben diesem.
Zur Lösung starte ich den Rechner mit einem Live- oder Rescue-System, ermittle die genaue Ursache und repariere diese.
Alternativ, falls ich gerade nicht von einem anderen Medium starten kann,
starte ich mit dem Kernelparameter init=/bin/sh eine Shell anstelle des
Init-Daemons.
Dann muss ich die Initialisierungen von Hand erledigen, bevor ich
das System reparieren kann.
No init found …
Der Kernel hat das Programm, das er als erstes starten soll, nicht gefunden.
Ich behandle das Problem ähnlich wie das vorige und starte ein Live- oder
Rescue-System beziehungsweise gebe mit der Option init=... ein
anderes Programm an.
Fatal Exception / Aiee, Killing Interrupt Handler
Diese Probleme können vielfältige Ursachen haben. Meist finden sich Hinweise
ein paar Zeilen weiter oben. Steht dort ein Oops, hat der Kernel ein
Problem erkannt und zunächst versucht weiter zu arbeiten.
Ein Oops ist eine Abweichung vom korrekten Verhalten des Kernels, die
eine Fehlermeldung produziert, welche via Syslog protokolliert werden kann.
Im Gegensatz dazu ist bei einem Kernel-Panic kein Logging mehr möglich.
Wenn der Kernel ein Problem entdeckt, gibt er eine Oops Nachricht aus und
beendet den verursachenden Prozess.
Die offizielle Dokumentation dazu findet sich in der Datei oops_tracing.txt
bei der Kernel-Dokumentation.
Sobald ein System einen Oops erlebt hat, arbeiten einige interne Ressourcen
nicht mehr korrekt.
Das wiederum kann zu weiteren Oops und schließlich zum Kernel-Panic führen.
Daher ist es bei der Analyse wichtig, sich zunächst auf den ersten Oops zu
konzentrieren.
Dabei helfen Internet-Suchen, die Dokumentation und gegebenenfalls eine Anfrage
auf der entsprechenden Mailingliste.
not syncing: VFS: Unable to mount rootfs on …
Der Kernel findet sein Root-Dateisystem nicht. Das kann an einem fehlenden oder defekten Initramfs liegen. Oder das in der Kernel-Kommandozeile genannte Dateisystem ist nicht erreichbar.
Als erstes sehe ich mir hier die Bootloader-Konfiguration genau an.
- Ist das Initramfs korrekt angegeben?
- Ist das Root-Dateisystem korrekt angegeben?
- Ist, bei NFS-Root, der Server mit dem Rootfs erreichbar und auf ihm das Dateisystem?
Manchmal muss ich den Rechner mit einem Live- oder Rescue-System starten, um das Problem genauer einzugrenzen und zu beheben.
Probleme im Initramfs
Bekomme ich Meldungen wie dracut: Warning: ... (Fedora) oder
Gave up waiting for root device (Debian, Ubuntu) und anschließend einen
Shell-Prompt, dann haben die Skripts des Initramfs das Root-Dateisystem nicht
gefunden.
Mit dmesg|less sehe ich mir die Kernelmeldungen noch einmal an.
Dabei suche ich nach Meldungen zu den Speichersystemen.
Habe ich less nicht zur Verfügung, kann ich mit <Shift>-<Bild auf/ab>
blättern.
Dabei überprüfe ich, ob die Systemplatte gefunden wurde, beziehungsweise bei
NFS-Root der Netzwerkadapter.
Falls das Root-Dateisystem als UUID oder Label spezifiziert wurde, kann ich
mit blkid alle Label und UUIDs ausgeben lassen.
Unter /proc und /sys kann ich weitere Informationen zu erkannter Hardware
finden.
So liefert mir /proc/mdstat zum Beispiel Informationen zu einem Software-RAID.
Udev
Kurz nachdem Udev gestartet wurde, bleibt das System hängen.
In diesem Fall helfen mir die Kerneloptionenudev.log_priority=info und udev.children-max=1.
Damit startet Udev nur einen Kind-Prozess und gibt eine Reihe von
zusätzlichen Informationen aus.
Habe ich damit ein problematisches Modul identifiziert, kann ich dieses mit
modulename.disable=1 in den Kernel-Optionen deaktivieren.
Stopp bei der Dateisystemüberprüfung
...
error checking filesystem
...
Give root password for rescue shell or type\
Control-D for reboot.
Der Init-Daemon hat ein Problem beim Dateisystemcheck erkannt und bietet mir an, dieses in einer Shell zu beheben. Dazu muss ich das Kennwort von root wissen.
Ein Neustart mit <CTRL>-D wird mir nicht weiterhelfen, da ich es hier mit
einem schwerwiegenden Problem im Dateisystem zu tun habe und beim nächsten
Start genauso weit kommen würde.
Ich brauche also das Kennwort oder eine andere Möglichkeit, eine
Root-Shell auf dem Rechner zu bekommen, wie zum Beispiel die Option
init=/bin/sh.
Dann starte ich die Dateisystemüberprüfung von Hand für alle benötigten Dateisysteme und starte den Rechner anschließend neu. Läuft der Rechner wieder, muss ich nun noch schauen, welche Dateien ich aus dem Backup ersetzen muss.
Bei einem fremden Rechner, oder wenn es ein älteres Gerät ist, zu dem ich keine
Aufzeichnungen habe, muss ich allerdings erst herausfinden, welche Partitionen
ich mit fsck überprüfen muss.
In der Bildschirmmeldung steht, bei welcher Partition die automatische
Überprüfung aufgegeben hat. Nötigenfalls kann ich mit <Shift>-<PgUp> nach oben
blättern, wenn die Meldung schon nach oben hinaus geschoben ist.
Je nach Alter des Rechners und verwendeter Linux Distribution steht da entweder ein Gerätename wie /dev/sda1, ein Label wie ``rootfs’’ oder eine UUID. Das fsck-Programm erwartet als Angabe einen Gerätenamen. Beim Label und bei der UUID muss ich die Zuordnung dafür herausbekommen.
Die Datei /etc/fstab kann ich als erste Anlaufstelle nehmen, die mir Hinweise auf die Partition und das Dateisystem gibt. Diese benötige ich, um das richtige Programm für die Dateisystemüberprüfung zu verwenden. Allerdings stehen in /etc/fstab auch nur Label beziehungsweise UUID, die ich aus der Konsolenmeldung bereits kenne.
Mit den verschiedenen Partitionierungsprogrammen kann ich mir die
Partitionen ausgeben lassen.
Insbesondere cfdisk ist hier nützlich, weil es vergebene Label anzeigt, so
dass ich sie einem Gerätenamen zuordnen kann.
Bei UUID hilft es mir leider nicht.
Das Programm blkid zeigt mir sowohl Label als auch UUIDs an:
# blkid
/dev/sda1: UUID="f7...4f" TYPE="ext3"
/dev/sda5: LABEL="swap" UUID="bc.." TYPE="swap"
Alternativ kann ich die Gerätedateien mit findfs bestimmen:
# findfs LABEL=swap
/dev/sda5
# findfs UUID=f779141e-...-9dde9de0b64f
/dev/sda1
Habe ich keines dieser Programme, stattdessen file, hilft das folgende
Vorgehen:
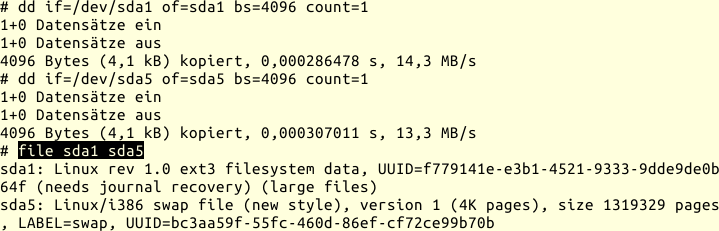
Partitionen mit file untersuchen
Da file bei der direkten Abfrage der Gerätedateien nur deren Typ angeben
würde, kopiere ich den ersten Block des Dateisystems in eine Datei und lasse
diese von file analysieren.
Bootprobleme virtueller Maschinen
Bei Problemen mit dem Start von virtuellen Maschinen ist es oft hilfreich, wenigstens die Bootpartition der betroffenen VM zu untersuchen.
Manchmal kann ich dazu das Festplattenimage der defekten VM einfach einer anderen VM zuordnen und es von dieser aus untersuchen. Das erscheint zumindest bei grafischen Oberflächen für die Administration als der einfachste Weg. Allerdings muss ich dann immer zwischen dem Hostsystem beziehungsweise der Administrationsoberfläche und der VM, mit der ich das Festplattenimage untersuche, wechseln. Dadurch verliere ich Zeit beim Zuordnen, Ein- und Aushängen und den Startversuchen.
Partitionen von Festplattenimages einhängen
Besser ist in meinen Augen, die Partitionen des betroffenen Images gleich im Hostsystem für die Analyse und Störungsbeseitigung einzubinden und die Vorteile der Shell für zügiges Arbeiten zu nutzen.
Dann habe ich das Problem, dass ich auf dem Hostsystem nicht, wie bei den eigenen Festplatten, die Partitionen direkt zur Verfügung habe, sondern nur das Komplettimage der Festplatte für die VM. Und dieses beginnt nicht mit dem Dateisystem sondern mit der Partitionstabelle. Um die gewünschte Partition einzubinden, muss ich dem Mount-Befehl den Offset der Partition mitgeben.
Den Offset kann ich mit dem Programm fdisk bestimmen.
Dieses listet mit der Option -l die Partitionen und deren Offsets auf.
Da ich letztere genau bestimmen muss, verwende ich zusätzlich die Option
-u, damit fdisk die Offsets als Anzahl von Sektoren zu je 512 Byte ausgibt:
# fdisk -l -u /dev/camion/ssh3
Disk /dev/camion/ssh3: 4294 MB, 4294967296 bytes
255 heads, 63 sectors/track, 522 cylinders, total\
8388608 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0x000c48f7
Device Boot Start End\
Blocks Id System
/dev/camion/ssh3p1 2048 7706623\
3852288 83 Linux
/dev/camion/ssh3p2 7708670 8386559\
338945 5 Extended
Partition 2 does not start on physical sector \
boundary.
/dev/camion/ssh3p5 7708672 8386559\
338944 82 Linux swap
Der Offset für die Systempartition ssh3p1 ist 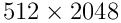 ,
also
,
also 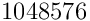 .
Damit kann ich diese Partition im Hostsystem wie folgt einhängen:
.
Damit kann ich diese Partition im Hostsystem wie folgt einhängen:
# mount /dev/camion/ssh3 /tmp/mnt \
-o loop,offset=1048576
Wenn ich fertig bin, hänge ich die Partition normal mit umount wieder aus.
Wichtig ist, dass ich die Partition im Hostsystem nur einhänge, wenn die VM nicht läuft. Das ist beim Untersuchen von Bootproblemen meist gegeben. Bei laufenden VMs habe ich mit LVM die Möglichkeit, einen Snapshot anzufertigen und diesen Snapshot nur-lesend einzuhängen. Dabei muss ich bedenken, dass Dateien, die in der VM geöffnet waren, vermutlich in einem inkonsistenten Zustand sind.
Fehlersuche im Initramfs
Ein wesentliches Element des Systemstarts ist das Initramfs. Das ist ein kleines Dateisystem, das der Bootloader zusammen mit dem Kernel in den Hauptspeicher lädt, und das für das Laden beim Start benötigter Treiber und deren Konfiguration zuständig ist. Damit ist es möglich, einen modularen Kernel, wie ihn die meisten Distributionen heutzutage verwenden, an unterschiedliche Hardware anzupassen. Somit ist es nur noch in seltenen Fällen nötig, einen Kernel speziell für eine bestimmte Maschine zu kompilieren.
Wie funktioniert das Initramfs?
Beim Systemstart lädt der Bootloader sowohl den Kernel als auch das
komprimierte Initramfs in den Hauptspeicher.
Anschließend startet er den Kernel und übergibt dabei die Kerneloptionen.
Der Kernel selbst reserviert einen Teil des Hauptspeichers und erzeugt darin
ein RAM-Dateisystem.
In dieses entpackt er das Initramfs.
Anschließend startet er das Skript init im Wurzelverzeichnis der RAM-Disk.
Alles weitere kann ich durch Analyse dieses Skripts erschließen, das ist von
Distribution zu Distribution verschieden.
Im Rahmen der Fehlersuche beschäftige ich mich mit dem Initramfs nur, wenn ein System nicht startet. Dabei interessieren mich vor allem zwei Fragen:
- Wie kann ich Fehler im Initramfs finden?
- Wie mache ich eine gefundene Lösung permanent?
Wie kann ich Fehler im Initramfs finden?
Ich suche den Fehler im Initramfs, wenn ich genau weiß, dass der Fehler nach dem Start des init Skripts und vor dem Einhängen des eigentlichen Root-Dateisystems passiert.
Bei den automatisch erzeugten Initramfs der verschiedenen Distributionen lande
ich bei Problemen manchmal in einer Shell und kann dann versuchen, mit
den Werkzeugen des Initramfs das Problem zu analysieren.
Da auf dem Initramfs fast immer busybox vorhanden ist, stehen mir hier oft
mehr Werkzeuge zur Verfügung, als auf den ersten Blick ersichtlich ist.
Bekomme ich keine Shell oder fehlt mir ein Werkzeug, muss ich das Initramfs modifizieren. Dabei kann ich das aktuelle als Ausgangsbasis nehmen.
Bei Debian-basierten Distributionen ist das Initramfs ein komprimiertes cpio-Archiv im Verzeichnis /boot. Dieses kann ich wie folgt entpacken:
# zcat /boot/initrd.img-$(uname -r) | cpio -idmv
Nun kann ich in den entpackten Verzeichnissen die Skripts anpassen und
gegebenenfalls weitere Programme installieren.
Dabei muss ich darauf achten, dass alle benötigten Bibliotheken vorhanden
sind.
Das kann ich mit chroot überprüfen.
Anschließend baue ich ein neues Initramfs:
# find . \
| cpio -oH newc \
| gzip -c > /boot/initrd-test.img
Anschließend muss ich dem Bootloader klarmachen, dass er das modifizierte Initramfs laden soll. Bei Grub ist das kein Problem, da ich die Booteinträge während des Bootvorgangs modifizieren kann. Bei anderen Bootloadern muss ich diesen gegebenenfalls neu konfigurieren und/oder installieren. Bei PXELINUX passe ich einfach die Datei im Verzeichnis pxelinux.cfg auf dem TFTP-Server an, so dass das modifizierte Initramfs geladen wird.
Wie mache ich meine Lösung permanent?
Habe ich im vorigen Schritt eine Lösung für mein Problem gefunden, dann will ich diese dauerhaft im System verankern. Hier kommt in’s Spiel, dass der Paketmanager bei jedem Kernelupdate oder der Installation von Kernelmodulen automatisch ein neues Initramfs erzeugt. Dabei ignoriert er meine Änderungen, wenn ich sie nicht an den richtigen Stellen unterbringe.
Permanente Änderungen bei Debian GNU/Linux
Bei Debian und darauf basierenden Distributionen sind diese Stellen:
- /etc/initramfs-tools/scripts - für eigene Skripts
- /usr/share/initramfs-tools/init - falls ich das init-Skript selbst modifizieren muss
- /etc/initramfs-tools/modules - für zusätzliche Module
- /etc/modprobe.d - für Moduloptionen
- /etc/udev/rules.d - für zusätzliche udev-Regeln
Nachdem ich die Änderungen eingearbeitet habe, erzeuge ich ein Initramfs nach Art des Hauses:
# update-initramfs -k $(uname -r) -u
Anschließend starte ich den Rechner neu und verifiziere meine Änderungen.
Magic SysRequest
Einem Totalausfall recht nahe kommt der Zustand, wenn ein oder mehrere Prozesse so viele Ressourcen belegen, dass andere Prozesse kaum noch zum Zuge kommen.
Erkennbar ist das zum Beispiel daran, dass Verbindungen über das Netz scheinbar noch funktionieren, der Rechner auf Ping antwortet, die Dienste des Rechners eventuell noch neue Verbindungen annehmen aber keine Antworten senden. An der Konsole kann ich beim Login noch Benutzername und Kennwort eingeben. Aber die Prüfung des Kennworts dauert so lange, dass sie durch Timeout abgebrochen wird. In einer Shell kann ich Befehle absetzen, aber ein Befehl, der einen neuen Prozess startet, dauert ewig.
Habe ich bereits einen Systemmonitor laufen, zeigt dieser mir mindestens eines dieser Symptome: die CPUs sind 100 Prozent ausgelastet, der Hauptspeicher ist voll, das System lagert ständig Speicherseiten aus und die Systemlast (die Anzahl der Prozesse, die auf Rechenzeit warten) ist sehr hoch.
Mit normalen Mitteln werde ich dieser Situation nicht mehr Herr, da ich nicht genug Einfluss nehmen kann. Als letzter Ausweg bliebe hier nur ein hartes Ausschalten des Systems mit den entsprechenden Folgen, wie Fehlern im Dateisystem und beschädigten Dateien. Bei einer sehr großen Platte würde es allein wegen des Dateisystemchecks ewig dauern, bis das System wieder einsatzfähig wäre.
Hier hilft mir der Magic SysRequest, wenn ich Zugang zur Konsole habe.
Der Magic SysRequest besteht aus der Tastenkombination <Alt> plus
<Druck> plus einer weiteren Taste, die eine bestimmte Funktion auslöst.
Um ein hängendes System geordnet neu zu starten, halte ich
<Alt> und <Druck> gedrückt und drücke dann nacheinander, mit
jeweils einigen Sekunden Abstand die Tasten r, e, i,
s, u, b. Als Eselsbrücke kann ich mir das Wort busier
(geschäftiger) rückwärts merken.
Die genannten Schlüsseltasten bewirken das folgende:
| r | X11 die Tastatur entziehen |
| e | alle Prozesse außer Prozess 1 mit SIGTERM beenden |
| i | alle Prozesse außer Prozess 1 mit SIGKILL abschießen |
| s | alle Dateisystempuffer auf Platte schreiben |
| u | alle Dateisysteme nur-lesend einhängen |
| b | Neustart |
Insbesondere die letzten drei Funktionen bewirken, dass der Kernel die
Dateisysteme vor dem Neustart sauber aushängt.
Damit sollte der Dateisystemcheck fehlerfrei laufen.
Mit dem zweiten Befehl (e) haben die Prozesse zumindest die Chance,
ihre geöffneten Dateien sauber zu schließen.
Dazu ist die Pause von einigen Sekunden vor dem nächsten Befehl (i)
notwendig.
Außer diesen sechs Funktionen bietet der Magic SysRequest noch weitere, deren Beschreibung ich in der Datei sysrq.txt in der Kerneldokumentation finde.
Damit Magic SysRequest überhaupt zur Verfügung steht, muss dieses Feature im
Kernel kompiliert sein.
Das ist bei den Kerneln der meisten Distributionen der Fall.
Die entsprechende Konfigurationsvariable heisst CONFIG_MAGIC_SYSRQ.
Außerdem muss es aktiviert sein.
Über die Datei /proc/sys/kernel/sysrq kann ich das kontrollieren.
Steht in dieser 0, ist Magic SysRequest deaktiviert.
Bei einer 1 sind alle Funktionen aktiv, bei einer höheren Zahl erfahre ich aus
der oben erwähnten Datei sysrq.txt, welche Funktionen aktiv sind.
Kernel Panic
Eine Kernel Panic ist eine Meldung des Kernels nachdem ein Fehler auftrat, auf Grund dessen sich das Betriebssystem in einem undefinierten Zustand befindet und nicht mehr kontrolliert weiter betrieben werden kann. Diese Meldung erscheint auf der Konsole zusammen mit weiteren Informationen, die für Laien meist unverständlich sind, dem Experten jedoch manchmal einen Hinweis auf die Ursache geben. Anschließend hält das Betriebssystem an.
Konsolenausgaben protokollieren
Um diese Informationen für spätere Auswertungen festzuhalten, kann ich eine serielle Schnittstelle als Konsole verwenden und deren Ausgaben auf einem anderen Rechner protokollieren. Bei virtuellen Maschinen zum Beispiel auf dem Hostsystem. Dazu muss ich dem Kernel beim Systemstart mitteilen, dass ich - zusätzlich zur normalen Konsole - eine serielle Schnittstelle verwenden will. Das geht mit folgender Option in der Kernel-Kommandozeile des Bootloaders:
console=ttyS0,38400
Damit behandelt der Kernel die erste serielle Schnittstelle als Konsole und stellt eine Schnittstellengeschwindigkeit von 38400 Baud ein. Die Konsolenausgabe kann ich in einer Datei protokollieren und bei Bedarf auswerten.
Crash-Dumps
Falls die Konsolenmeldungen nicht ausreichen, um das dahinter liegende Problem zu bestimmen, habe ich bei einem neueren Kernel die Möglichkeit, im Fall einer Kernel Panic mit kdump einen Dump des Kernelspeichers auf ein geeignetes Medium schreiben zu lassen. Kdump verwendet den kexec Systemaufruf, um einen Dump-Capture-Kernel zu starten mit dem ich einen Speicherabzug des alten Kernels sichern kann.
Das Speicherabbild des alten Kernels bleibt während des Reboots erhalten und ist für den neuen Kernel zugänglich. Wenn der neue Kernel gestartet ist, kann ich das Speicherabbild für die spätere Analyse mit Bordmitteln (cp, scp, ftp) sichern. Details finden sich in der Datei kdump/kdump.txt in der Kernel-Dokumentation.
Zur Analyse selbst starte ich wieder den Standard-Kernel.