9. Grundlagen IP-Netzwerke
Ein paar Grundlagen benötige ich immer wieder, wenn ich die Vorgänge in einem IP-Netzwerk verstehen will.
Insbesondere halte ich bei der Fehlersuche die Kenntnis folgender Themen für wichtig:
- Das OSI-Referenzmodell, mit dessen Hilfe ich die Position eines Protokolls im Protokoll-Stack bestimmen und seine Bedeutung einschätzen kann.
- ARP, weil es die Lücke schließt zwischen dem Internet-Protokoll und der Netzzugangsschicht, wie zum Beispiel Ethernet.
- Die Bestimmung von IPv4-Netzmasken.
- Die Zustände von TCP-Verbindungen.
- Zwei wesentliche Algorithmen bei Routing-Protokollen: Distanz-Vektor und Link-State.
Auf diese Themen gehe ich in den folgenden Abschnitten ein, damit wir sie im positiven Sinne vergessen können.
OSI-Modell
Ein wichtiges Modell für die Betrachtung von Netzwerkverbindungen ist das Open Systems Interconnection Model. Dieses dient als Referenzmodell für Netzwerkprotokolle und ist als Schichtenmodell ausgeführt. Es gibt keine Implementierung des OSI-Modells, dieses dient lediglich der Einordnung realer Protokolle und der Kommunikation darüber. In diesem Modell gibt es sieben aufeinanderfolgende Schichten mit jeweils begrenzten Aufgaben. Jede Instanz einer Schicht nutzt die Dienste der Instanzen der nächsttieferen Schicht und stellt ihre Dienste den Instanzen der nächsthöheren Schicht zur Verfügung. Die folgenden Schichten sind im OSI-Modell definiert:
| deutsche Bezeichnung | englische Bezeichnung | |
|---|---|---|
| 7 | Anwendungsschicht | application layer |
| 6 | Darstellungsschicht | presentation layer |
| 5 | Sitzungsschicht | session layer |
| 4 | Transportschicht | transport layer |
| 3 | Vermittlungsschicht | network layer |
| 2 | Sicherungsschicht | data link layer |
| 1 | Bitübertragungsschicht | physical layer |
Die Instanzen auf Sender und Empfängerseite müssen nach festgelegten Regeln (dem Protokoll) arbeiten und bilden dann eine logische horizontale Verbindung über diese Schicht. Die in der gleichen Schicht definierten Netzwerkprotokolle mit klar definierten Schnittstellen sind, abhängig von ihren spezifischen Eigenschaften, untereinander austauschbar.
Reale Protokolle bilden mitunter mehrere Schichten des OSI-Modells ab. Zum Beispiel:
- Ethernet die Schichten 1 und 2
- IP, ICMP, IGMP die Schicht 3
- TCP, UDP die Schicht 4
- HTTP, SMTP, LDAP die Schichten 5, 6, und 7
Betrachte ich die Kopplungselemente in einem Computernetzwerk, so decken die heute kaum noch gebräuchlichen Hubs und Repeater die Schicht 1 ab, Bridges und Switche die Schichten 1 und 2, Router die Schichten 1 bis 3 und schließlich Protokoll-Gateways die Schichten 1 bis 7.
ARP - Address Resolution Protocol
Für die Zuordnung von Adressen der Netzzugangsschicht (OSI-Schichten 1 und 2) zu denen der Internetschicht (OSI-Schicht 3) dient bei IPv4 das ARP-Protokoll. Es ist in RFC 826 beschrieben und in RFC 5527 sowie RFC 5494 aktualisiert und ergänzt. Für IPv6 wird dafür das Neighbor Discovery Protocol verwendet, das RFC 4861 beschreibt.
Ein Rechner, der via Ethernet eine Verbindung zu einem anderen mit einer
IP-Adresse im direkt angeschlossenen Segment aufbauen will,
sendet eine ARP-Anfrage mit seiner Ethernet- und IP-Adresse als Quelle und der
IP-Adresse des Partners als Ziel an die Ethernet-Broadcast-Adresse
(ff:ff:ff:ff:ff:ff).
Erhält der Ziel-Rechner diese ARP-Anfrage, antwortet er direkt an den
anfragenden Rechner.
Daraufhin aktualisiert der Anfragende seinen ARP-Cache.
Zusätzlich kann der Angefragte seinerseits den Cache mit den
Daten der Anfrage aktualisieren.
Das ist vom Protokoll jedoch nicht vorgegeben.
ARP funktioniert grundsätzlich nur im direkt angeschlossenen Netzsegment und nicht über Router. Es ist jedoch möglich, dass ein Router stellvertretend für die IP-Adressen, zu denen er Routen kennt, ARP-Anfragen beantwortet. Das nennt man Proxy-ARP. Proxy-ARP setze ich zum Beispiel ein, wenn zwei Netzsegmente zwar durch Router getrennt sind, aber als ganzes Segment erscheinen sollen. Im Gegensatz zur Kopplung mit einer Bridge werden in diesem Fall keine Broadcasts zwischen den Teilnetzen ausgetauscht.
Dann gibt es noch Gratuitous ARP, bei dem der Sender seine Adressen sowohl bei der Quelle als auch beim Ziel einträgt. Diese sollten normalerweise nicht beantwortet werden. Eine Antwort auf Gratuitous ARP ist ein Indiz für eine Fehlkonfiguration. Gratuitous ARP werden manchmal beim Booten eines Rechners versendet, in Hochverfügbarkeitsszenarien, wenn eine IP-Adresse auf eine andere MAC-Adresse umgeschaltet werden soll, sowie bei Mobile-IP-Lösungen.
Schließlich ist ARP Bestandteil bei Zero Configuration Networking, speziell bei Dynamic Configuration of IPv4 Link-Local Addresses (RFC 3927), um dynamisch eine IP-Adresse zu bestimmen, die nur für das lokale Segment gültig ist. Für diesen Zweck ist der Adressbereich 169.254.0.0/16 reserviert.
IPv4-Netzmasken
An dieser Stelle will ich ein paar Worte zu IPv4-Netzmasken verlieren. Zu einer Zeit, in der IPv6 langsam an Fahrt gewinnt, mutet das vielleicht etwas anachronistisch an. Leider wird IPv4 noch fast überall eingesetzt und die Kenntnis der Netzgrenzen ist bei der Fehlersuche in IPv4-Netzen Grundvoraussetzung. Es lohnt sich daher für den Netzwerk-Troubleshooter nach wie vor, diese zu memorieren, falls er nicht in der Lage ist, sie in annehmbarer Zeit im Kopf auszurechnen.
Prinzipiell gibt es zwei Schreibweisen:
- in Bitnotation: /0 .. /32
- in Vierer-Notation: 0.0.0.0 .. 255.255.255.255
mit Hexadezimalzahlen: 0.0.0.0 .. FF.FF.FF.FF.
Beide Schreibweisen lassen sich in einander umrechnen. Beide müssen beherrscht werden, da einige Programme nur entweder die eine oder die andere verwenden können.
Bei der Umrechnung helfen die ehemaligen Netzwerkklassen mit ihrer Größenunterteilung in 8-Bit-Grenzen. In der folgenden Tabelle habe ich die drei Klassen A, B, C um die Notation für den gesamten IPv4-Adressbereich auf der einen Seite und für einen einzelnen Host auf der anderen Seite ergänzt:
| Bits | Vierergruppen | Anzahl Hosts | |
|---|---|---|---|
| alle Adressen | /0 | 0.0.0.0 | > 4 Milliarden |
| Class A Size | /8 | 255.0.0.0 | > 16 Millionen |
| Class B Size | /16 | 255.255.0.0 | > 65 Tausend |
| Class C Size | /24 | 255.255.255.0 | 254 |
| Host | /32 | 255.255.255.255 | 1 |
Interessanter sind die Subnetz- oder CIDR-Masken. Für diese gehe ich von der Netzmaske der nächstgrößeren Klasse aus und füge die entsprechende Anzahl Bits (1..7) hinzu. In Viererschreibweise (VS) ändert sich die Position, die bei der klassenbasierten Adresse die erste 0 hat.
| Bits | VS | Hex | Netzadressen |
|---|---|---|---|
| /+1 | 128 | 80 | 0, 128 |
| /+2 | 192 | C0 | 0, 64, 128, 192 |
| /+3 | 224 | E0 | 0, 32, 64, 96, 128, … |
| /+4 | 240 | F0 | 0, 16, 32, 48, 64, … |
| /+5 | 248 | F8 | 0, 8, 16, 24, 32, … |
| /+6 | 252 | FC | 0, 4, 8, 12, 16, … |
| /+7 | 254 | FE | 0, 2, 4, 6, 8, … |
Die Netzadresse gibt an, an welcher Adresse ein Netz beginnt. Diese Adresse kann ich nicht für Hosts vergeben. In der Tabelle habe ich nur maximal die ersten fünf Netzadressen aufgeführt. Die weiteren ergeben sich, indem man die erste oder zweite zu allen Netzadressen der nächsthöheren Zeile addiert. Die zugehörige Broadcast-Adresse ist die Adresse des nächsten Netzwerkes mit gleicher Bitmaske, vermindert um 1.
Nehmen wir als Beispiel einen Host mit der IPv4-Adresse10.21.32.43/21.
Die Netzmaske ist /16+5, in Vierernotation 255.255.248.0.
Die Netzadresse ist 10.21.32.00, die Broadcastadresse ist 10.21.39.255.
In diesem Segment stehen 2046 Adressen für Hosts zur Verfügung.
Wer die IPv4-Netzmasken nicht selbst ausrechnen möchte, kann sich das Programm ipcalc ansehen, das bei einigen Distributionen mitgeliefert wird. Dieses kommt mit einem CGI-Wrapper, so dass es auch als Netzdienst eingerichtet werden kann.
Kommunikationsbeziehungen
In Rechnernetzen gibt es neben der paarweisen Kommunikation einzelner Rechner verschiedene Kombinationen, die unter den Begriffen Unicast, Broadcast, Multicast und Anycast zusammengefasst werden.
Wenn ich ein Netzwerkproblem analysiere, muss ich wissen, mit was für Verkehr ich es zu tun habe und was das bedeuten kann.
Unicast
Kommuniziert genau ein Rechner mit genau einem definierten anderen, spricht man von einer Unicast-Verbindung.
Diese Verbindung kann über das gesamte Netzwerk gehen, also mehrere Segmente überspannen.
Beispiele dafür sind HTTP und SMTP.
Broadcast
Will ein Rechner alle anderen Rechner in einem Netzsegment erreichen, verwendet er bei IPv4 Broadcast-Nachrichten. Diese sind immer auf ein Subnetz beschränkt und werden an Broadcast-Adressen versendet, von denen es zwei Arten gibt: globale und subnetzspezifische Broadcast-Adressen.
Die globale Broadcast-Adresse (255.255.255.255) hat alle Bits gesetzt. Mit dieser Adresse kann ich alle Rechner im direkt angeschlossenen Subnetz erreichen, unabhängig vom Netzwerkpräfix. Router leiten Datagramme an diese Adresse nicht weiter. Früher konnte ich mit einem PING an die globale Broadcast-Adresse auf einfache Weise herausfinden, ob ich mindestens einen im gleichen Segment angeschlossenen Rechner erreichen kann. Heutzutage beantwortet kaum ein Rechner noch einen PING an die Broadcast-Adresse, wenn er nicht explizit dafür konfiguriert wurde.
Bei der subnetzspezifischen Broadcast-Adresse sind nur die Hostbits der Adresse gesetzt, zum Beispiel ist 192.168.1.255 die Broadcast-Adresse für das Netz 192.168.1.0/24. Diese Adresse richtet sich an alle Rechner in einem Subnetz. Datagramme an subnetzspezifische Adressen wurden früher auch über Router transportiert. Da das jedoch für die Verstärkung von DoS-Angriffen ausgenutzt wurde, unterbinden heute viele Router diesen Verkehr.
Die Protokolle ARP und RIP in Version 1 sind zwei Protokolle, die Broadcast-Adressierung verwenden.
In IPv6 wurden Broadcast-Funktionen durch Multicast ersetzt.
Multicast
Bei Multicast kommuniziert ein Sender oder eine relativ geringe Anzahl von Sendern mit mehreren Empfängern. Diese Kommunikation kann über mehrere Router gehen, wenn diese entsprechend konfiguriert sind. Die Reichweite ist genau bestimmt, da die Empfänger sich für Multicast-Adressen beim Gateway registrieren müssen und die Gateways ihrerseits das Routing von Multicast untereinander aushandeln.
Bei IPv4 ist für Multicast der Netzbereich 224.0.0.0/4 vorgesehen. Davon ist der Bereich 224.0.0.0/24 reserviert für Routingprotokolle und ähnliche Dienste für die Topologieerkennung und -wartung.
Bei IPv6 erkennt man eine Multicast-Adresse an den acht höchstwertigen Bits der Adresse. Sind alle gesetzt, handelt es sich um eine Multicast-Adresse, ansonsten ist es eine Unicast-Adresse. RFC 4291 spezifiziert die Adressarchitektur von IPv6 und geht in Abschnitt 2.7 auf Multicast-Adressen ein.
Service Location Protocol und RIP in Version 2 verwenden Multicast.
Anycast
Bei der Adressierung mit Anycast verwenden mehrere Rechner dieselbe Adresse. Das führt im selben Netzsegment natürlich zu Kollisionen, darum werden die Rechner mit der gleichen Adresse in verschiedenen Netzsegmenten platziert und die Anycast-Adresse über Routingprotokolle im Netz bekannt gemacht.
Anycast-Adressierung wird eingesetzt, um Traffic einzusparen, indem verschiedene Instanzen desselben Dienstes unter derselben Adresse an verschiedenen Stellen im Netz möglichst nahe bei den Clients des Dienstes platziert werden.
Neben dem eingesparten Datenverkehr ist ein weiterer Vorteil, das bei Ausfall eines Servers automatisch der nächstgelegene übernimmt, sobald das Routingprotokoll wieder konvergiert ist und den Verkehr auf diesen umleitet.
Ein Problem bei Anycast ist die Synchronisation der Daten, die anycast-adressierte Server anbieten. Auch können Sitzungsdaten nicht einfach auf den neuen Server übernommen werden. Daher eignet sich Anycast nicht für alle Dienste.
Für den Server ist eine anycast-addressierte Verbindung eine normale Unicast-Verbindung. Für den Client ist es, ohne Kenntnis der Routen im Netz, nicht möglich, anzugeben, an welchen Server die Datagramme gesendet werden.
Eine länger laufende Anycast-Verbindung kann durch Änderungen beim Routing irreversibel gestört werden. Bei Protokollen mit kurzen Transaktionen, wie DNS, ist dieses Problem jedoch unerheblich.
Problematisch kann die Zeit für die Konvergenz des Routingprotokolls sein, wenn der Server sich nicht abmeldet, weil er plötzlich vom Netz getrennt wurde.
Daher ist neben der direkten Überwachung der Server eine Überwachung des Routings angezeigt.
Anycast wird zum Beispiel bei den DNS-Rootservern verwendet.
Zustände einer TCP-Verbindung
Ich betrachte hier die Zustände einer TCP-Verbindung, weil TCP vermutlich das am häufigsten im Netz vorkommende Protokoll ist. Außerdem ist es komplex genug, um sich wenigstens mit den grundlegenden Interna zu beschäftigen damit ich das Verhalten der Beteiligten im Störungsfall einschätzen kann.
Verbindungsaufbau
Beim Aufbau einer TCP-Verbindung haben wir immer eine passive Seite - üblicherweise der Server, bei FTP auch manchmal der Client - und eine aktive Seite. Die passive Seite beginnt im Zustand LISTEN.
Ein erfolgreicher Verbindungsaufbau benötigt drei Datenpakete und geht wie folgt vonstatten:
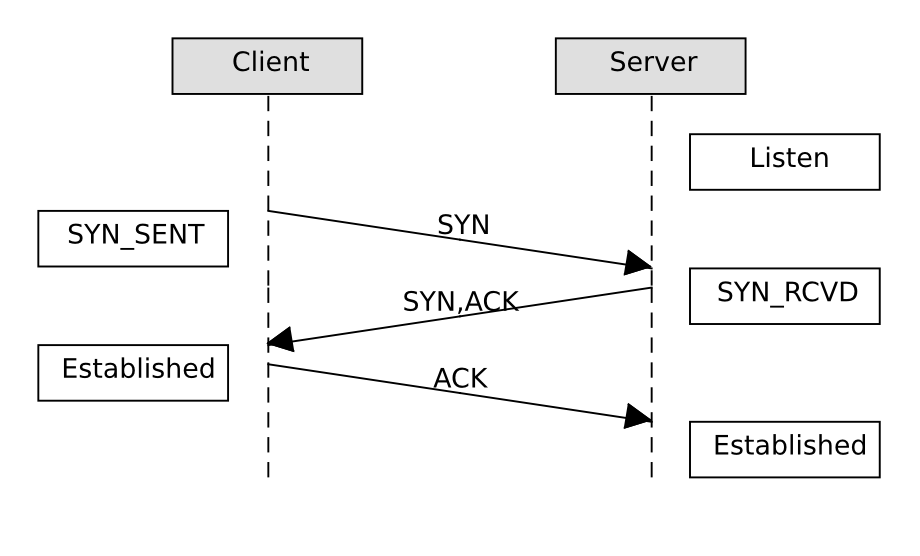
TCP Verbindungsaufbau
Der Client sendet ein SYN-Paket (das ist ein TCP-Datagramm mit gesetztem SYN-Flag) und geht in den Zustand SYN_SENT. Sobald das SYN-Paket beim Server ankommt, bestätigt dieser es mit einem SYN-ACK-Paket und geht in den Zustand SYN_RCVD. Der Client bestätigt das SYN-ACK-Paket mit ACK und geht in den Zustand ESTABLISHED. Sobald das ACK-Paket beim Server ankommt geht dieser ebenfalls in den Zustand ESTABLISHED und die Verbindung ist vollständig etabliert.
Nur bei den ersten beiden Datenpaketen kann ich vom Netzwerk aus sehen, welche Seite die Verbindung aktiv aufgebaut hat.
Wenn an dem betreffenden Port auf Serverseite kein Prozess lauscht oder der Server eine Verbindung abweist, sieht das wie folgt aus:
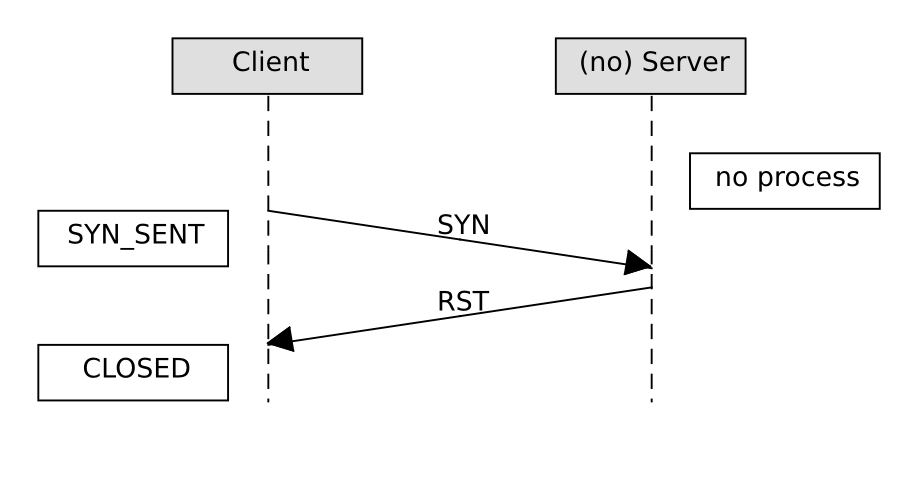
TCP Verbindungsaufbau gescheitert
Der Client sendet wie eben ein SYN-Paket. Von Serverseite aus folgt unmittelbar ein RST-Paket und schon ist es vorbei. Alternativ kann der Server auch ein ICMP-Paket vom Typ 3 (Destination unreachable) mit Code 3 (Port unreachable) senden, das ist jedoch eher für das Protokoll UDP üblich.
Ist stattdessen der Serverport durch Paketfilter-Regeln gesperrt, kommt vom Server gar nichts und der Client wiederholt sein SYN-Paket noch einige Male, bevor er aufgibt.
Verbindungsabbau
Während für den TCP-Verbindungsaufbau drei Datenpakete reichen, benötigt TCP für den Abbau einer Verbindung vier Datenpakete. Da sowohl Client als auch Server die Verbindung zuerst schließen können, nenne ich die beteiligten Parteien hier A und B:
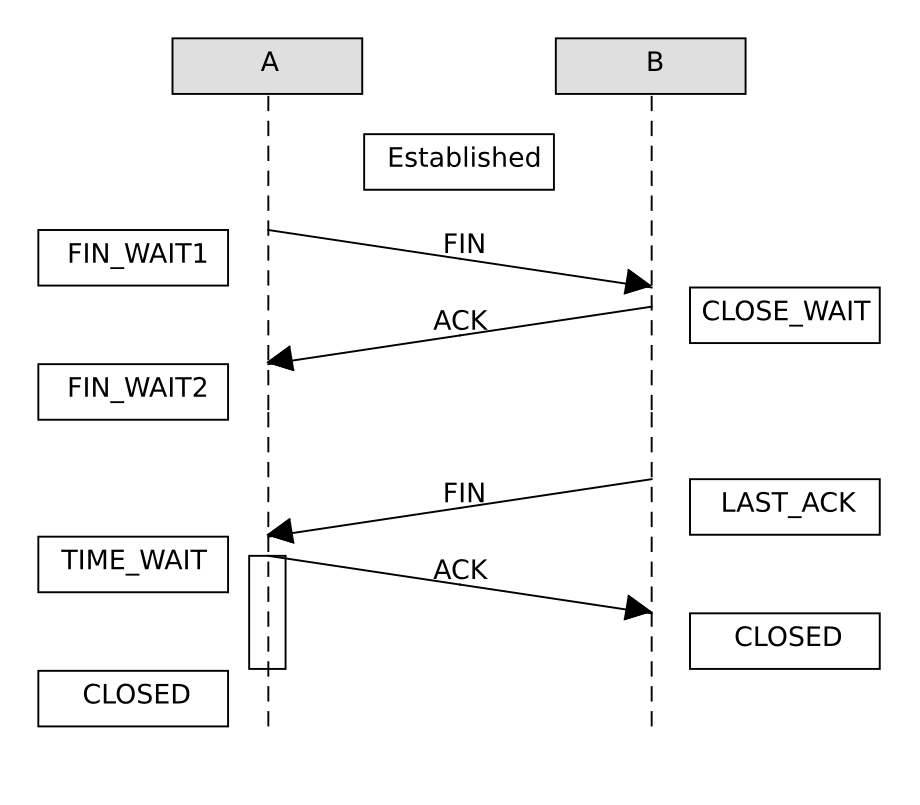
TCP Verbindungsabbau
A schließt auf seiner Seite einseitig die TCP-Verbindung indem er ein FIN-Paket sendet, anschließend geht er in den Zustand FIN_WAIT1. B bestätigt das FIN-Paket normal mit ACK und geht in den Zustand CLOSE_WAIT. Jetzt könnte B noch Daten über die halbgeschlossene Verbindung senden, A sendet keine Daten mehr, nur noch ACK. Irgendwann sendet B ebenfalls ein FIN-Paket und geht in den Zustand LAST_ACK über. Sobald A das FIN-Paket empfängt, bestätigt es dieses mit ACK und geht für die doppelte MSL in den Zustand TIME_WAIT und danach in den Zustand CLOSED. B geht mit Empfang der Bestätigung von A sofort in den Zustand CLOSED.
Da A noch eine Zeit lang im Zustand TIME_WAIT verbleibt, kann ich solange
mit netstat -ant sehen, dass dieser die Verbindung
zuerst geschlossen hat.
Flusssteuerung
In [ctZivadinovic2012] erläutert der Autor die Funktionsweise der TCP-Flusskontrolle ausführlich und sehr anschaulich.
Es gibt zwei Aspekte bei der TCP-Flusssteuerung. Zum einen teilt der Empfänger dem Sender mit, wie viele Bytes er momentan verarbeiten kann. Zum anderen will der Sender die Datenrate so steuern, dass die Daten so schnell wie möglich, aber mit möglichst geringen Verlusten durch Überlastung der Leitung übertragen werden.
Für das erste Problem gibt es im TCP-Header das Feld RWIN (Receive Window). In dieses trägt der Empfänger den momentan freien Platz im Empfangspuffer ein. Ein Receive Window von 0 bringt die Datenübertragung zum Erliegen und deutet darauf hin, dass der Empfänger die Daten nicht schnell genug verarbeiten kann. Das kann ein Hinweis sein, bei Performanceproblemen die Situation auf dem empfangenden Rechner in Augenschein zu nehmen.
Neben der Anzahl der beim Empfänger eintreffenden Datenpakete begrenzt das Receive Window auch die maximal erreichbare Datenübertragungsrate, abhängig von der RTT zwischen Sender und Empfänger. Die RTT beträgt im LAN typischerweise weniger als eine Millisekunde, innerhalb Deutschlands etwa fünfzig Millisekunden und interkontinental mehr als hundert Millisekunden. Der Sender sendet maximal soviel Daten, wie im Receive Window vorgegeben, ohne Bestätigung durch ACK-Pakete an den Empfänger.
Die folgende Tabelle soll den Einfluß der RTT auf die erzielbare Datenrate verdeutlichen. Bei einer Erhöhung der RTT um das zehnfache sinkt die Datenrate um den Fakter zehn, wenn das Receive Window gleich bleibt.
| RWIN | RTT (ms) | Datenrate (MB/s) |
|---|---|---|
| 50000 | 1 | ~ 50 |
| 50000 | 10 | ~ 5 |
| 50000 | 100 | ~ 0,5 |
Darum ist es bei Breitbandverbindungen mit hoher RTT hilfreich, das Receive Window des Empfängers zu erhöhen, wenn die maximal mögliche Datenübertragungsrate nicht erreicht wird.
Da TCP bereits 1981 entwickelt wurde, ist das Parameterfeld für das Receive
Window nur 16 Bit groß, der Maximalwert liegt also bei 65535.
Aus diesem Grund gibt es in modernen TCP-Stacks die Möglichkeit des Windows
Scaling.
Dabei wird beim Verbindungsaufbau ein Multiplikator für das RWIN-Feld
ausgehandelt, der für beide Seiten verbindlich ist.
Dieser Multiplikator ist eine Potenz von zwei und kann von 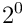 bis
bis
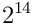 reichen,
beim Aushandeln der Verbindung wird nur der Exponent übertragen.
reichen,
beim Aushandeln der Verbindung wird nur der Exponent übertragen.
Für die Flusssteuerung zur Vermeidung von Überlast gibt es verschiedene Algorithmen, die zum Teil gemeinsam verwendet werden können. Der Sender führt für die Verbindung ein Congestion Window, das ihm anzeigt, wieviel Bytes er momentan auf die Leitung schicken könnte.
Slow Start und Congestion Avoidance
Bei diesem Verfahren startet die Datenübertragung mit einem Congestion Window von einer Maximum Segment Size (MSS) und erhöht diese mit jedem empfangenen ACK um eine MSS. Das führt zu einem exponentialen Wachstum des Congestion Windows.
Bei Erreichen der Slow Start Threshold wird das Congestion Windows nur noch um eine MSS erhöht, wenn alle Datenpakete aus dem aktuellen Fenster bestätigt wurden. Das führt zu einem linearen Wachstum des Congestion Window.
Wird durch Timeout der Verlust eines Datenpakets festgestellt, beginnt dass Congestion Window wieder bei einer MSS.
Fast Retransmit und Fast Recovery
Hierbei informiert der Empfänger den Sender über mögliche Paketverluste sobald er Datenpakete außer der Reihe empfängt. Dazu bestätigt er das letzte Datenpaket in der richtigen Reihenfolge mit jedem neu ankommenden Datenpaket außer der Reihe durch DUP-ACK (Duplicate Acknowledgements). Der Sender sendet das verlorene Datenpaket sofort nach dem dritten DUP-ACK und wartet nicht auf den Timeout. Das Congestion Window wird in diesem Fall nur halbiert und nicht wie bei Slow Start auf ein MSS reduziert.
Selective Acknowledgements (SACK)
Zusätzlich zum letzten regulären Paket bestätigt der Empfänger in den DUP-ACK die außer der Reihe angekommenen Datenpakete in zusätzlichen TCP-Headerfeldern, so dass diese nicht noch einmal gesendet werden müssen.
Path-MTU
Die Maximum Transmission Unit (MTU) beschreibt die maximale Größe eines Datenpakets, die auf einem Netzsegment ohne Fragmentierung gesendet werden kann. Dementsprechend ist die Path-MTU die maximale Größe eines Datenpakets, das durch alle Segmente vom Empfänger zum Sender ohne Fragmentierung übertragen werden kann.
Um ein Datenpaket, das größer ist als die MTU eines Netzsegmentes, zu übertragen, muss dieses in kleinere Datenpakete zerlegt (Fragmentierung) und nach der Übertragung wieder zusammen gefügt werden. Das hat mehrere Nachteile:
- Das Zerlegen und Zusammensetzen kostet zusätzlichen Speicherplatz und Rechenzeit.
- Die nutzbare Bandbreite reduziert sich, weil zusätzliche Protokollinformationen mit den Fragmenten gesendet werden müssen, um sie am Ende zusammensetzen zu können.
- Firewalls können bei fragmentierten Datenpaketen nicht immer korrekte Entscheidungen treffen, müssen die Datenpakete also ebenfalls zusammensetzen, was zusätzliche Leistung kostet.
- Es gibt Angriffe gegen Rechner, die fragmentierte Datenpakete verwenden.
Das sind für mich genug Gründe, warum ich in meinen Netzen möglichst keine fragmentierten Datenpakete haben will.
RFC 1191 beschreibt die Mechanismen für die automatische Bestimmung der Path-MTU.
Im Grunde läuft es darauf hinaus, dass der Sender in den IP-Optionen der
gesendeten Datagramme das Don’t fragment Bit setzt.
Kommt ein Datagramm mit dieser Option an einen Router mit einer kleineren MTU
auf dem weiteren Weg, dann verwirft dieser das Datagramm und sendet an den
Absender eine ICMP-Unreachable-Nachricht mit dem Code fragmentation needed
and DF set und der MTU des nächsten Segments.
Der Absender kann die Path-MTU für die betroffene Verbindung anpassen und die
Daten in kleineren Datenpaketen versenden.
Für TCP gibt es außerdem die Möglichkeit, beim Aushandeln der Verbindung die Maximum Segment Size in den Optionen anzugeben. Diese sollte nicht größer sein als das größte fragmentierte Datagramm, dass der Empfänger noch zusammensetzen kann. Fehlt diese Option soll der Sender maximal 576 Byte große Datagramme senden, was einer MSS von 536 entspricht. RFC 1191 empfiehlt stattdessen, die MTU des Netzsegmentes zu verwenden und immer beim Verbindungsaufbau auszuhandeln. In diesem Fall stört die MSS nicht die automatische Bestimmung der Path-MTU, so dass der Datenpfad optimal ausgenutzt werden kann.
Routing-Algorithmen
Heute eingesetzte Routing-Protokolle basieren meist auf einem von zwei Algorithmen: dem Distanzvektor-Algorithmus oder dem Link-State-Algorithmus.
Beide sind verteilte Algorithmen, bei denen jeder Router für sich selbst die optimale Route zu einem Netzbereich ermittelt. Demgegenüber steht der Ansatz von OpenFlow bei Routern und Switches der erlaubt, die Routen zentral zu berechnen und dann an die verschiedenen Router und/oder Switches zu verteilen. Dieser Ansatz erlaubt experimentelle Routing-Algorithmen auszuprobieren, ohne dass man an der Hardware oder Routersoftware etwas ändern muss.
Bei den verteilten Algorithmen muss man einen Kompromiss finden zwischen dem nötigen Netzverkehr für das Routingprotokoll und der Rechenleistung für die Berechnung der Routen. Bei Routingprotokollen mit Distanzvektor-Algorithmus steigt der Datenverkehr für das Routingprotokoll sehr stark mit der Vergrößerung des Netzwerks, bei den Routingprotokollen mit Link-State-Algorithmus steigt der Rechenaufwand stärker.
Für die Betrachtung der beiden Algorithmen verwende ich diese Routerkonstellation.
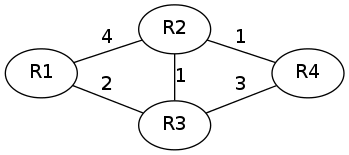
Router-Graph
Die Knoten des Graphen stehen für die beteiligten Router, die Zahlen an den Kanten geben die Metrik für die Verbindung zwischen den beiden verbundenen Routern wieder.
Distanzvektor-Algorithmus
Die Protokolle RIP und RIP2 verwenden diesen Algorithmus.
Dabei informiert jeder Router alle direkten Nachbarn über alle ihm selbst bekannten Routen nebst deren Metriken. Jeder Router, der Informationen von seinen Nachbarn erhält, fügt neu bekannt gewordene Routen zu seiner eigenen Routingtabelle hinzu und behält bei bereits bekannten Routen diejenige mit der kleinsten Metrik.
Distanzvektor-Protokolle werden auch als Routing nach Gerücht bezeichnet. Fehlerhafte Routinginformationen verbreiten sich hier genau so schnell wie gute.
Für die weitere Betrachtung nehme ich an, dass immer zuerst Router R1 seine Routen bekannt gibt, dann R2, R3 und schließlich R4.
Am Anfang kennt jeder Router nur seine nächsten Nachbarn.
| Router | Ziel | Weg | Metrik |
|---|---|---|---|
| R1 | R2 | direkt | 4 |
| R1 | R3 | direkt | 2 |
| R2 | R1 | direkt | 4 |
| R2 | R3 | direkt | 1 |
| R2 | R4 | direkt | 1 |
| R3 | R1 | direkt | 2 |
| R3 | R2 | direkt | 1 |
| R3 | R4 | direkt | 3 |
| R4 | R2 | direkt | 1 |
| R4 | R3 | direkt | 3 |
Wenn R1 seine Routen bekanntgibt ändert sich daran nichts.
Sendet R2 seine Routen, ändert sich folgendes:
| Router | Ziel | Weg | Metrik |
|---|---|---|---|
| R1 | R4 | R2 | 5 |
| R3 | R4 | R2 | 2 |
| R4 | R1 | R2 | 5 |
| R4 | R3 | R2 | 2 |
Nachdem R3 seine Routen gesendet hat ändern sich die folgenden Einträge:
| Router | Ziel | Weg | Metrik |
|---|---|---|---|
| R1 | R2 | R3 | 3 |
| R1 | R4 | R3 | 4 |
| R2 | R1 | R3 | 3 |
Wenn schließlich R4 seine Routen bekannt gibt, ändert sich nichts an den Routingeinträgen. Das gleiche trifft für den nächsten Update von R1 zu.
Wenn R2 das nächste Mal seine Routen bekannt gibt, ändert sich zwar keine Route aber eine Metrik
| Router | Ziel | Weg | Metrik |
|---|---|---|---|
| R4 | R1 | R2 | 4 |
Danach sind die Routen und Metriken stabil, bis eine Änderung auftritt.
Am Router R1 sieht die Routingtabelle im stabilen Zustand wie folgt aus:
| Router | Ziel | Weg | Metrik |
|---|---|---|---|
| R1 | R2 | R3 | 3 |
| R1 | R3 | direkt | 2 |
| R1 | R4 | R3 | 4 |
An diesem relativ einfachen Beispiel ist zu sehen, dass der Algorithmus manchmal mehrere Zyklen braucht, bis die Routingeinträge zu einem stabilen Zustand finden. Bei den Protokollen RIP und RIP2 dauert ein Zyklus 30 Sekunden.
 |
Ausgehend vom stabilen Zustand, entferne eine beliebige Route und spiele die Routingänderungen durch bis zum Erreichen eines neuen stabilen Zustands. |
Link-State-Algorithmus
Das Protokoll OSPF verwendet den Link-State-Algorithmus.
Dieser Algorithmus arbeitet in zwei Schritten: zunächst erstellt jeder Router anhand der Zustandsinformationen über die Verbindungen seiner Nachbarn, die er von diesen erhält, eine topologische Karte (einen Graphen) des gesamten Netzwerks, bei der die Knoten die Router darstellen und die Kanten die gewichteten Verbindungen zwischen diesen. Im zweiten Schritt errechnet der Routing-Prozess auf jedem Router mit Hilfe des Dijkstra-Algorithmus den optimalen Pfad zu allen bekannten Netzen.
Dijkstra-Algorithmus
- Der Routing-Prozess trägt alle Knoten in eine Tabelle Q ein und weist ihnen die Distanz unendlich zu und einen unbekannten Vorgänger. Dem Startknoten, also dem Router, auf dem der Prozess läuft weist er dann die Entfernung 0 zu.
- Solange es noch Einträge in der Tabelle Q gibt, wählt der
Routing-Prozess daraus den Eintrag mit der geringsten Distanz aus.
- Der ausgewählte Knoten wird aus der Tabelle Q entfernt und in Tabelle R eingetragen. Für diesen Knoten ist die kürzeste Distanz bereits bestimmt.
- Für alle direkten Nachbarn des ausgewählten Knoten wird die Distanz bestimmt. Ist die Distanz geringer als in der Tabelle Q, wird die Distanz in der Tabelle Q durch die neu bestimmte ersetzt und der ausgewählte Knoten als Vorgänger eingetragen.
Die Distanz wird dabei bestimmt aus der Summe der Distanz des eben entfernten Knotens und dem Kantengewicht zwischen diesem und dem betrachteten Knoten.
Wenn wir den Dijkstra-Algorithmus am Router R1 für den oben angeführten Router-Graph durchspielen wollen, initialisieren wir die Tabelle Q wie folgt:
| Knoten | Vorgänger | Distanz |
|---|---|---|
| R1 | unbekannt | 0 |
| R2 | unbekannt | unendlich |
| R3 | unbekannt | unendlich |
| R4 | unbekannt | unendlich |
In der ersten Runde entfernen wir R1 aus Tabelle Q, bestimmen die Distanz für alle noch in Q enthaltenen direkten Nachbarn von R1.
| Knoten | Vorgänger | Distanz |
|---|---|---|
| R2 | R1 | 4 |
| R3 | R1 | 2 |
| R4 | unbekannt | unendlich |
Nun entfernen wir R3 und bestimmen wieder die Distanz für dessen in Q verbleibende Nachbarn.
| Knoten | Vorgänger | Distanz |
|---|---|---|
| R2 | R3 | 3 |
| R4 | R3 | 5 |
Dann entfernen wir R2 und bestimmen die Distanz für R4 neu.
| Knoten | Vorgänger | Distanz |
|---|---|---|
| R4 | R2 | 4 |
Schließlich entfernen wir den letzten Knoten, R4 und haben nun folgende Pfad-Tabelle R am Router R1:
| Knoten | Vorgänger | Distanz |
|---|---|---|
| R1 | unbekannt | 0 |
| R2 | R3 | 3 |
| R3 | R1 | 2 |
| R4 | R2 | 4 |
Diese Tabelle enthält die Pfade zu allen Zielen im Netz. Damit daraus eine für den Kernel brauchbare Routing-Tabelle wird, müssen wir die Pfade auf den jeweiligen Next-Hop abbilden:
| Ziel | Next-Hop | Distanz |
|---|---|---|
| R1 | selbst | 0 |
| R2 | R3 | 3 |
| R3 | direkt | 2 |
| R4 | R3 | 4 |
Es ist leicht zu sehen, dass bei diesem Algorithmus relativ wenige Informationen über das Netz gesendet werden müssen. Nämlich für jeden Router nur die Distanz zu den Nachbarn und die direkt angeschlossenen Netze, während beim Distanzvektor-Algorithmus jeder Router alle ihm bekannten Routen sendet. Demgegenüber ist der Rechenaufwand hier für jeden einzelnen Knoten höher als beim Distanzvektor-Algorithmus.
Dafür konvergiert dieser Link-State-Algorithmus schneller, weil sämtliche Routen sofort berechnet werden können, sobald der vollständige Graph bekannt ist.
|
|
Bestimme die Routing-Tabelle für die anderen Router mit dem Dijkstra-Algorithmus. |