7. Performance des Rechners
Der Rechner funktioniert zwar, aber alles erscheint zäh und in Zeitlupe abzulaufen. Jobs brauchen eine gefühlte Ewigkeit, die Tastatur scheint mit 8 Baud angeschlossen. Irgendwo sind Engpässe, aber wo?
Oft ist es einfach nur eine Überlast, das heißt, das System erhält temporär mehr Aufgaben, als es bewältigen kann. Dann werde ich zunächst alles tun, um die Last zu reduzieren. Anschließend mache ich mir Gedanken, wie ich die zu erwartende Last bewältigen kann.
Die drei wesentlichen Engpässe beim Betrieb eines Rechners sind CPU,
Hauptspeicher und I/O.
Welcher von diesen drei im Moment gerade den Betrieb hemmt, bekomme ich sehr
schnell mit dem Befehl vmstat heraus.
Damit weiß ich allerdings erst, wo ich suchen will, die eigentliche Ursache
muss ich noch ermitteln.
Mit dem Programm top kann ich etwas genauer hinschauen.
Je nach dem, was ich mit vmstat herausbekommen habe, kann ich interaktiv mit
P die Prozesse nach prozentualer Nutzung der CPU und mit M nach der
prozentualen Nutzung des Speichers sortieren lassen.
Mit 1 zeigt das Programm in den Kopfzeilen für jede einzelne CPU an, wie sie
ihre Zeit verbringt.
Mit f, gefolgt von j und <Enter> zeigt das Programm in einer
zusätzlichen Spalte, welcher Prozess auf welcher CPU läuft.
Wenn ich es ganz genau wissen will, erstelle ich ein Lastprofil meines Systems mit Accounting-Software wie sysstat. Zwar belastet diese das System zusätzlich, doch ich kann die Ergebnisse meiner Analyse dann nutzen, um gezielt in neue Hardware zu investieren, ein oder mehrere leistungsstärkere Prozessoren, mehr RAM, schnellere Festplatten und Netzwerkkarten. Oder ich verteile die Last auf mehrere Systeme.
Als Einführung in das Gebiet empfehle ich Loukides1996, das mittlerweile in neuer Auflage erschien.
Engpass CPU
Habe ich festgestellt, dass die CPU den Engpass des Systems bildet, dann will
ich als nächstes wissen, was sie gerade macht.
Mit vmstat habe ich nicht nur herausbekommen, dass die CPU bremst, sondern
auch, ob sie mehr im Userland, das heißt mit dem Code des Benutzerprogramms
und den Bibliotheken, oder mehr im Systembereich, also mit dem Kernelcode,
beschäftigt ist.
Außerdem kann ich an Hand der Anzahl der Interrupts und Kontextwechsel einschätzen, ob die CPU vorwiegend mit wenigen Prozessen zu tun hat oder oft zwischen verschiedenen Programmen hin und her springt. Im letzteren Fall kann das Abschalten einiger Dienste zu einer spürbaren Entlastung führen.
Welche Prozesse die meiste Rechenzeit benötigen, ermittle ich mit top und
ps.
Dabei setze ich top ein, um interaktiv die Prozesse mit der meisten
Systemzeit zu finden.
Mit ps sortiere ich die Prozesse wie folgt:
$ ps k-%cpu
PID TTY STAT TIME COMMAND
4288 ? Sl 1:16 /usr/lib/firefox/firefox
3578 tty7 Rs+ 0:39 /usr/bin/X :0 -auth ...
4086 ? Sl 0:08 gnome-terminal
...
5212 pts/3 R+ 0:00 ps k-%cpu -e
5213 pts/3 S+ 0:00 less
Habe ich im Moment keine Möglichkeit, weitere Dienste zu beenden, kann ich mit
renice den Scheduler anweisen, bestimmte Prozesse höher oder niedriger zu
priorisieren, so dass er diesen mehr oder weniger Rechenzeit zuteilt.
Langfristig kann ich mit Systemaccounting den Ressourcenbedarf der einzelnen Programme festhalten und diesen für weitere Entscheidungen heranziehen. Dabei muss ich bedenken, dass die Accounting-Programme zwar den Ressourcenbedarf mehr oder weniger gut erfassen und Hilfe für die allgemeine Dimensionierung des Rechners geben können, aber im konkreten Überlastfall keine direkte Hilfe bieten. Sie können im Nachhinein zeigen, ob bestimmte Programme mehr Ressourcen als üblich benötigt haben oder häufiger als sonst gelaufen sind. Außerdem benötigen die Accounting-Programme selbst Ressourcen und tragen auf diese Weise mit zum Problem bei.
Einige Programme lassen sich so konfigurieren, dass sie weniger Ressourcen verbrauchen. Da ich dazu keine allgemeinen Hinweise geben kann, verweise ich auf die Dokumentation der entsprechenden Software. Ist das nicht möglich, kann ich das Programm vielleicht durch ein anderes ersetzen, welches weniger Ressourcen benötigt.
Bei modernen Prozessoren habe ich oft die Möglichkeit, die Taktfrequenz der
CPU per Software zu manipulieren.
Falls die CPU momentan nicht mit der maximal möglichen Taktfrequenz arbeitet,
kann ich diese mit den cpufrequtils bei einem Engpass kurzfristig anheben.
Das Programm cpufreq-info zeigt mir Informationen zur aktuellen und zu
einstellbaren Taktfrequenzen.
Mit cpufreq-set ändere ich die Einstellungen.
Schließlich habe ich noch die Möglichkeit, durch Hardware-Erweiterungen das System zu beschleunigen. Eine oder mehrere zusätzliche CPU, schnellere CPU oder Hardware-Beschleuniger für Verschlüsselungen können das Problem mitunter eliminieren.
Eventuell muss ich die Dienste des Systems auf mehrere Maschinen verteilen. Das kann ich auf verschiedene Art machen: ich kann mehrere gleich konfigurierte Systeme nehmen und die Last zwischen diesen aufteilen, ich kann die verschiedenen Teilaufgaben auf verschiedene Maschinen verteilen, zum Beispiel eine Maschine für die Verschlüsselung, eine für die Anwendung und eine für die Datenbank. Und natürlich kann ich beide Formen gleichzeitig verwenden und mischen.
Performance Monitoring Unit der CPU
Seit Jahren gibt es in den Prozessoren Performance-Counter, spezielle Zähler in der Performance Monitoring Unit (PMU) der CPU. Diese ermitteln Leistungsdaten, die ich zur Analyse der Laufeigenschaften von Programmen einsetzen kann.
Da die Mechanismen von CPU zu CPU unterschiedlich sind, gab es lange keine einheitliche Schnittstelle unter Linux, um diese Daten zu nutzen.
Mit perf gibt es nun jedoch ein Werkzeug, das eine einheitliche
Schnittstelle für den Zugang zu diesen Daten bietet. In dem Artikel
[ctHM2013] geben die Autoren einen Einblick in die
Funktionsweise der Performance-Counter und die Anwendung von perf.
Weitere Hinweise und ein Tutorial kann ich im
Perf Wiki finden.
Engpass RAM
Wenn ich mit den Programmen free, vmstat oder interaktiv mit top
herausbekommen habe, dass der Hauptspeicher momentan der Flaschenhals des
Systems ist, will ich nun herausfinden, was konkret den gesamten Hauptspeicher
aufbraucht und was ich dagegen unternehmen kann.
Um ein Programm in einem Prozess abzuarbeiten, kopiert der Kernel es zuvor
aus dem Dateisystem in den RAM.
Dabei kopiert er nur die Speicherseiten, die als nächstes abgearbeitet werden
sollen und nicht das komplette Programm.
Das gleiche Programm, wenn es in verschiedenen Prozessen abläuft,
wird nur einmal kopiert, lediglich den Stack und
den Heap hat jeder Prozess für sich allein.
Ein Programm, wie busybox, dass viele andere Programme ersetzen kann,
spart Speicherplatz im RAM und im Dateisystem.
Für Overlay-Dateisysteme, tmpfs oder loopback-Mounts benötige ich weiteren RAM. Dieser Speicher steht den Prozessen nicht als Arbeitsspeicher zur Verfügung.
Schließlich verwendet der Kernel den Speicher, der noch nicht für oben genannte Zwecke verwendet wurde, als Pufferspeicher für Dateizugriffe. Darum muss ich mich nicht kümmern, da der Kernel diesen Speicher automatisch freigibt und für andere Zwecke verwendet.
Der Hauptspeicher der X86-Rechnerarchitektur wird in drei Bereiche unterteilt:
- ZONE_DMA
- von 0 bis 16 MiB. Dieser Bereich enthält Speicherseiten, die Geräte für DMA nutzen können.
- ZONE_NORMAL
- von 16 MiB bis 896 MiB. Dieser Bereich enthält normale regulär eingeblendete Speicherseiten.
- ZONE_HIGHMEM
- ab 896 MiB. Dieser Bereich enthält Speicherseiten, die nicht dauerhaft in den Adressbereich der 32-Bit-CPU eingeblendet sind.
Analyse der Speichernutzung
Um die Speichernutzung eines Linux-Systems zu analysieren, greife ich
auf die Programme free, top, ps und pmap zurück.
Das Programm free zeigt mir einen Überblick zur momentanen Belegung
des gesamten nutzbaren Systemspeichers:
$ free
total used free shared buffers cached
Mem: 255488 135984 119504 0 6588 108732
-/+ buffers/cache: 20664 234824
Swap: 0 0 0
Dabei sehe ich unter total nie den gesamten Speicher, weil der vom Kernel selbst und der von der Hardware verwendete Teil heraus gerechnet wird.
Der Speicher unter buffers enthält temporäre Daten der laufenden Prozesse, also Eingangsqueues, Dateipuffer und Ausgabequeues. Der als cached markierte Speicher enthält zwischengespeicherte Dateizugriffe.
Mit dem Programm top kann ich einzelne Prozesse, die besonders viel
Speicher verbrauchen, näher eingrenzen.
Es liefert in den Kopfzeilen eine Übersicht über die Prozesse, die CPU-Last
und den Gesamtspeicherverbrauch und darunter eine Tabelle mit den Daten
einzelner Prozesse.
Die Ausgabe wird laufend aktualisiert und lässt sich anpassen.
Mit ? erhalte ich eine Hilfeseite über die möglichen Modifikationen.
Mich interessiert in diesem Fall die Sortierung nach Speicherverbrauch,
die ich durch Eingabe von m bekomme.
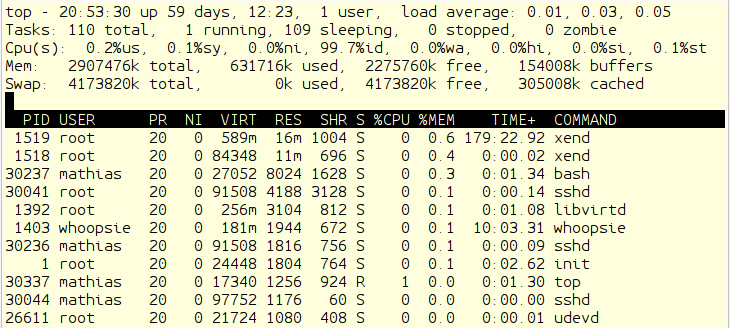
top - sortiert nach Speicherbedarf
Für die Speicheranalyse interessieren mich vor allem vier Spalten:
- VIRT
- steht für die virtuelle Größe des Prozesses. Diese setzt sich zusammen aus dem eingeblendeten Speicher, in den Adressbereich eingeblendeten Dateien und Speicher, den der Prozess mit anderen teilt. Mit anderen Worten, der Speicher auf den ein Prozess gerade Zugriff hat. Darin ist auch der ausgelagerte Speicher enthalten.
- RES
- steht für resident size, den physischen Speicher, den der Prozess belegt. Dieser geht in die Berechnung der %MEM Spalte ein.
- SHR
- ist der Anteil von VIRT, den der Prozess mit anderen teilen kann.
- %MEM
- ist der prozentuale Anteil eines Prozesses am verfügbaren physischen Speicher.
Mit dem Programm ps bekomme ich einen Schnappschuss des momentanen Speicherverbrauchs aller Prozesse:
$ ps aux
USER PID %CPU %MEM VSZ RSS ...COMMAND
root 1 0.0 0.2 2024 676 ...init [2]
...
mathias 9042 0.0 0.3 2344 904 ...ps aux
Um die Prozesse mit dem größten Speicherverbrauch zu finden, sortiere ich nach Spalte 6, RSS:
$ ps aux|sort -n -k6 -r |head
mathias 9006 0.1 1.9 6220 4928 ...-bash
snmp 1031 0.1 1.6 8832 4268 .../usr/sbin/snmpd
ntp 954 0.0 0.7 4576 1920 .../usr/sbin/ntpd
root 9005 0.0 0.4 2396 1048 .../usr/sbin/dropb
root 898 0.0 0.3 3808 928 .../usr/sbin/cron
mathias 9054 0.0 0.3 2344 908 ...ps aux
root 2260 0.0 0.3 2960 900 .../usr/sbin/pppd
dnsmasq 842 0.0 0.3 4116 840 .../usr/sbin/dnsma
mathias 9057 0.0 0.3 2036 768 ...less -S
root 220 0.0 0.2 2252 720 ...udevd --daemon
Für die Speicheranalyse interessieren mich die Spalten VSZ (virtual set size), RSS (resident set size) und PID (process id). Die PID, um damit den Prozess mit pmap zu untersuchen:
$ sudo pmap -d 1031
1031: /usr/sbin/snmpd -Lsd -Lf /dev/null -u snmp...
Address Kbytes Mode Offset...Mapping
08048000 24 r-x-- 000000...snmpd
0804e000 4 rw--- 000000...snmpd
09cd4000 1156 rw--- 000000... [ anon ]
b70bf000 40 r-x-- 000000...libnss_files-2.11.2.so
b70c9000 4 r---- 000000...libnss_files-2.11.2.so
b70ca000 4 rw--- 000000...libnss_files-2.11.2.so
...
b77c7000 4 r-x-- 000000... [ anon ]
b77c8000 108 r-x-- 000000...ld-2.11.2.so
b77e3000 4 r---- 000000...ld-2.11.2.so
b77e4000 4 rw--- 000000...ld-2.11.2.so
bfc54000 332 rw--- 000000... [ stack ]
mapped: 8828K writeable/private: 2172K shared: 0K
Der in der letzten Zeile als writeable/private bezeichnete Speicher ist der, den der Prozess nur für sich verbraucht und nicht mit anderen teilt.
Swappiness
Falls, trotz aller Bemühungen, der Speicher im System knapp wird, kann ich ab Kernel 2.6 zumindest darauf Einfluss nehmen, ob der Kernel eher Prozesse und Daten auslagert (swapping), oder eher die Caches verkleinert, wenn der Speicher zur Neige geht. Das geht mit dem Parameter Swappiness, der als Zahl von 0 .. 100 eingestellt wird. Dabei bedeutet 100, das der Kernel eher auslagert und 0, dass der Cache sehr klein werden kann. Die Standardeinstellung ist 60, für Laptops wird ein Wert kleiner oder gleich 20 empfohlen. Diesen Parameter kann ich zur Laufzeit ändern:
# sysctl -w vm.swappiness = 30
oder:
# echo 30 > /proc/sys/vm/swappiness
Falls mein System ohne Auslagerungsspeicher läuft, ist das jedoch irrelevant.
Engpass Ein-/Ausgabe
Stelle ich fest, dass das System wenig bis gar keinen Hauptspeicher auslagert und die CPU ihre Zeit nicht zum größten Teil im User- oder Kernelcode sondern wartend verbringt, dann habe ich es mit einem Engpass beim I/O-Subsystem zu tun.
Probleme bei Ein- und Ausgabe können durch das Netzwerk verursacht sein, darum kümmere ich mich im dritten Teil des Buches. Sie können durch spezielle Hardware verursacht werden, das lasse ich außen vor, weil diese Probleme nur mit eben dieser Hardware gelöst werden können. Oder, sie kommen durch Plattenzugriffe zustande, die ich optimieren kann. Darum geht es in dem folgenden Abschnitt.
Wenn ich die Platten-Performance verbessern will, brauche ich ein gewisses Grundverständnis über die Zusammenhänge und die Stellen, an denen ich schrauben kann, sowie eine Möglichkeit, das Ergebnis meiner Bemühungen zu verifizieren.
Grundlagen
Benutzerprogramme greifen auf Daten, die auf Festplatte gespeichert sind, meist über Dateien im Dateisystem zu. Einige Datenbanksysteme arbeiten statt mit Dateien direkt mit den Blockdevices, die die Festplatte beziehungsweise deren Partition repräsentieren. Da bei diesen Datenbanksystemen meist in der Dokumentation Anleitungen zum Performancetuning zu finden sind, lasse ich auch diese außen vor.
Ich betrachte als oberste Abstraktion für den Zugriff auf
Festplattendaten Dateien in den mit mount eingebundenen Dateisystemen.
Auf dieser Ebene nehme ich Einfluss auf die Performance durch die Wahl des
Dateisystems und die Parameter für mount beim Einhängen in den Dateibaum.
Die nächsttiefere Ebene ist das Blockdevice, welches das Dateisystem trägt. Hier habe ich selten eine Wahl bezüglich des Treibers. Bei speziellen Blockdevices, wie zum Beispiel verschlüsselten Partitionen, stehen mir mitunter Alternativen offen, die ich gegeneinander abwägen muss. Habe ich mehrere Festplatten und mehr Plattenplatz als ich benötige, kann ich durch die Wahl geeigneter RAID-Level das System für meinen Bedarf optimieren. Dabei darf ich neben der Geschwindigkeit die Datensicherheit nicht aus den Augen lassen.
Schließlich komme ich zur untersten Schicht, dem Festplattencontroller und der
Plattenelektronik.
Für den Anschluss der Festplatte gibt es verschiedene Systeme, wie IDE, SCSI,
SATA, SAS, die ich bei fertigen Systemen und konkreten Festplatten nicht mehr
ändern kann.
Allerdings habe ich die Möglichkeit, durch Änderung einiger Parameter die
Übertragung der Daten zu beschleunigen.
Diese Parameter stelle ich mit dem Programm hdparm ein.
Halten wir fest, dass ich die Geschwindigkeit der Dateizugriffe beeinflussen kann durch:
- die Wahl der Hardware und Übertragungsmodi
- den Kerneltreiber, dessen Optionen und gegebenenfalls den RAID-Level
- die Wahl des Dateisystems und der Optionen beim Einhängen desselben in den Dateibaum
Verifizierung der Tuningmaßnahmen
Um mich zu vergewissern, dass mein Tuning erfolgreich war, muss ich die Performance vor und nach den Änderungen messen und protokollieren. Dafür habe ich verschiedene Möglichkeiten.
Die einfachste und fast immer verfügbare ist das Lesen und Schreiben von Daten
mit dd.
Dieses Programm ist auf fast allen Systemen installiert, mit speziellen
Optionen kann ich es anweisen, Dateizugriffe synchron zu schreiben oder direkt
zu lesen, so dass ich den Einfluss der Dateipuffer eliminieren kann.
Dann brauche ich nur die Zeit zu messen und kann die Geschwindigkeit für
sequentielles Lesen und Schreiben ermitteln.
Um neben der sequentiellen Lese- und Schreibgeschwindigkeit auch die
Performance bei wahlfreiem Zugriff einzuschätzen, kann ich auf bonnie++
zurückgreifen.
Dieses Programm liefert mir die Auswertungen in übersichtlichen Tabellen,
die das Vergleichen erleichtern.
Schließlich kann ich mit dem Programm fio gezielt ganz bestimmte I/O-Lasten
erzeugen.
Wichtig bei all diesen Messverfahren ist, dass das System unbelastet von anderen Aufgaben ist, damit ich die Messungen vergleichen kann.
Monitoring
Habe ich kein unbelastetes System, an dem ich in Ruhe meine Messungen machen
kann, sondern ein stark belastetes, dem ich helfen will, greife ich zu
top und iostat.
Bei top schalte ich mit den Tasten F und dann u die Anzeige um, so dass
sie nach Pagefaults sortiert wird.
Damit kenne ich die Prozesse, welche die meisten Ein- und Ausgaben machen und
kann mir überlegen, wie ich die dadurch verursachte Last reduziere.
Der Befehl
$ iostat -p -xk
zeigt mir, auf welchen Partitionen geschrieben, beziehungsweise gelesen wird.
Mit fuser und lsof kann ich die Dateien und Verzeichnisse ermitteln und
auf eine andere Platte verschieben, um die Last gleichmäßiger
zu verteilen.
Tuningmaßnahmen
Die Einstellungen sollten vor Inbetriebnahme des Systems erfolgen. Ist es produktiv, bleibt oft keine Zeit für größere Maßnahmen.
Wenn es möglich ist, eine weitere Platte einzubauen, kann ich damit die Last
besser verteilen und so das System entlasten.
Dazu bestimme ich mit iostat, fuser und lsof die bisherige Auslastung und
die Lage der Dateien, um sie dann geschickter zu verteilen.
Dateien mit ähnlichen Zugriffsmustern sollten auf der selben Partition liegen,
wenn ich die Partitionen über mount Optionen optimiere.
Auf Festplatten, rotierenden Scheiben, sollten so wenige Partitionen wie möglich sein, bei mehreren häufig genutzten Partitionen muss der Lesekopf sonst unnötig große Wege zurücklegen.
RAID0 kann die Lesegeschwindigkeit erhöhen, RAID1 die Schreibgeschwindigkeit. Gerade bei letzterem darf ich die Datensicherheit nicht aus dem Auge verlieren.
Mit hdparm kann ich verschiedene Parameter des Plattencontrollers und der
Plattenelektronik einstellen.